Data Mining¶
Knowage supports advanced data analysis allowing you to extract knowledge from large volumes of data, to improve your decision-making and business strategies. In particular, Knowage Data Mining Engine integrates Python scripting capabilities.
Thanks to Knowage Data Mining Engine, it is possible to execute Python scripts in an interactive way and enrich traditional datasets with new information. This means that it allows users to perform statistical or data mining analysis on different Knowage datasets.
The data scientists can thus integrate its own algorithm within Knowage and deliver their output to the end user, together with new advanced visualization options useful to discover meaningful insights hidden in the data.
Functions Catalog¶
The Data Mining can be managed through the Functions framework. In this section we will see how to explore and handle this part, while in Use a function inside documents we will see how to use functions.
First click on the Functions Catalog from the Knowage main page as shown below.
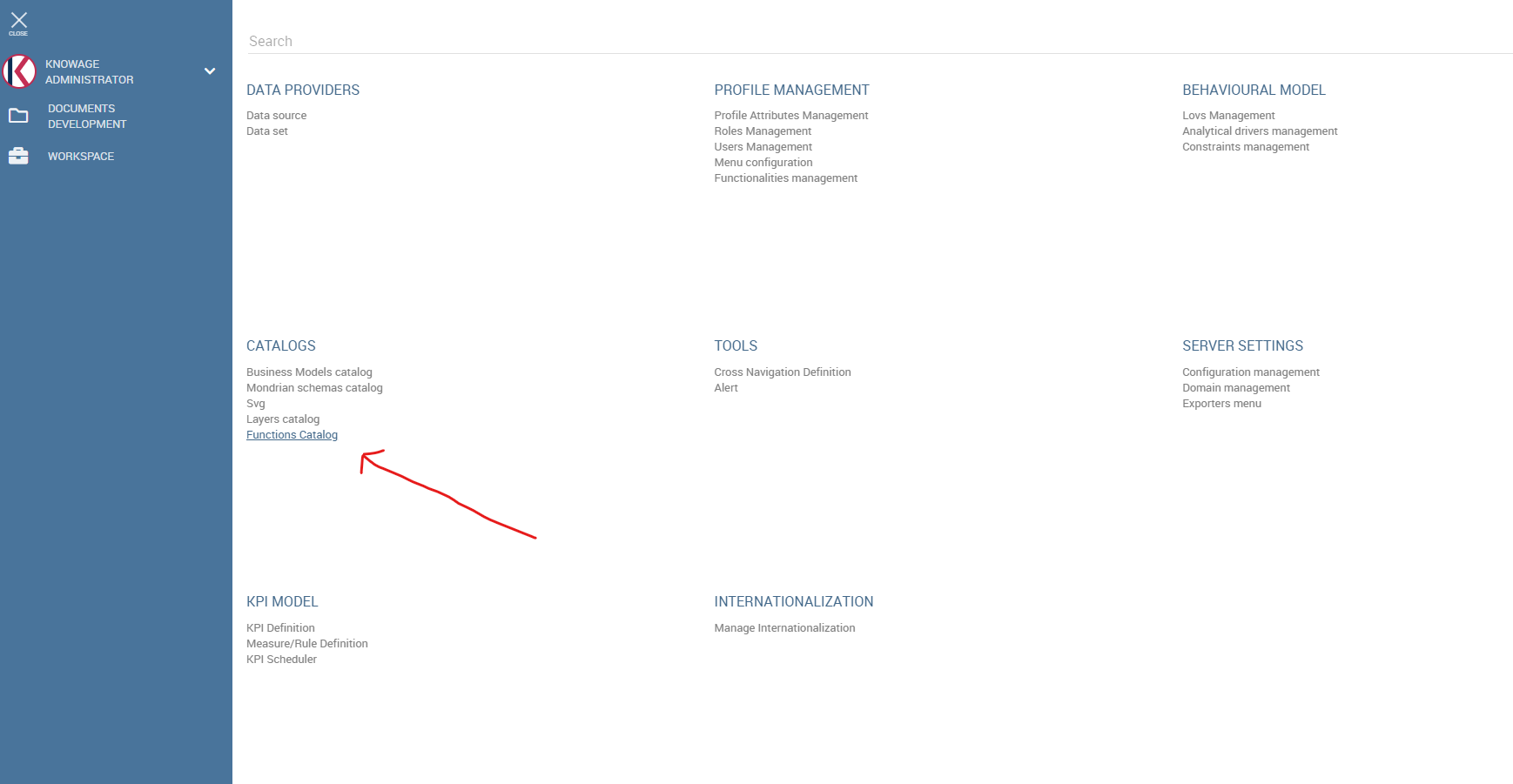
Functions Catalog from Knowage menu.¶
You will enter a page like the one shown in figure below.
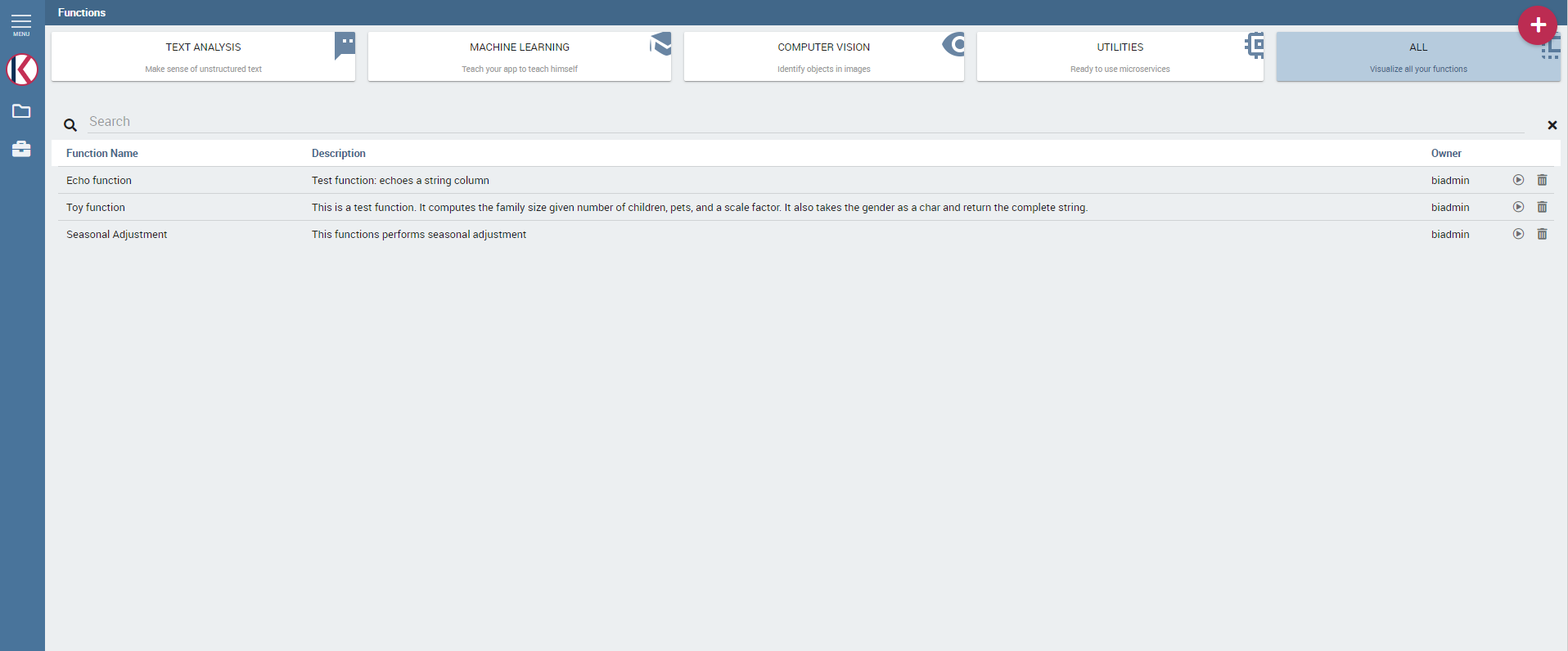
Functions Catalog interface.¶
The actions that a user can perform depend on the user’s role. However, independently from the user’s role, once entered the feature all functions are shown by default. Referring to the figure above, one has the page made up of:
categories: these are set by an administrator user and are used to classify the functions accordingly to their definition and goals. Moreover they’re of help in browsing the functions; only the admin user can add and/or modify categories.
tags: they are used to easily sharpen the research and easily recall the functions that are tagged with that word; once again only the admin user can add and/or modify tags;
list of functions (if there are any): these are visible and explorable by any kind of user. Anyway only an admin user can add and/or modify them.
Hint
Add or modify the categories
The admin can add a new category using the Domain management available on Knowage Server under the Server Settings section. To know more about this section, please refer to Section “Server settings” of the General Administration Manual.
The categories for functions depends on an admin user. Taking Functions Catalog interface figure as an example, we have:
Text Analysis: make sense of unstructured text,
Machine Learning: teach your app to teach himself,
Computer Vision: identify objects in images,
Utilities: ready to use microservices,
All: visualizes all your functions; this is the only category that cannot be changed or removed.
To facilitate the comprehension we created some functions to be examined. We recall here that one can look for a function in different ways: using the categories or the tags or using the Functions Catalog “Search” box available at the top of the functions list as highlighted below.
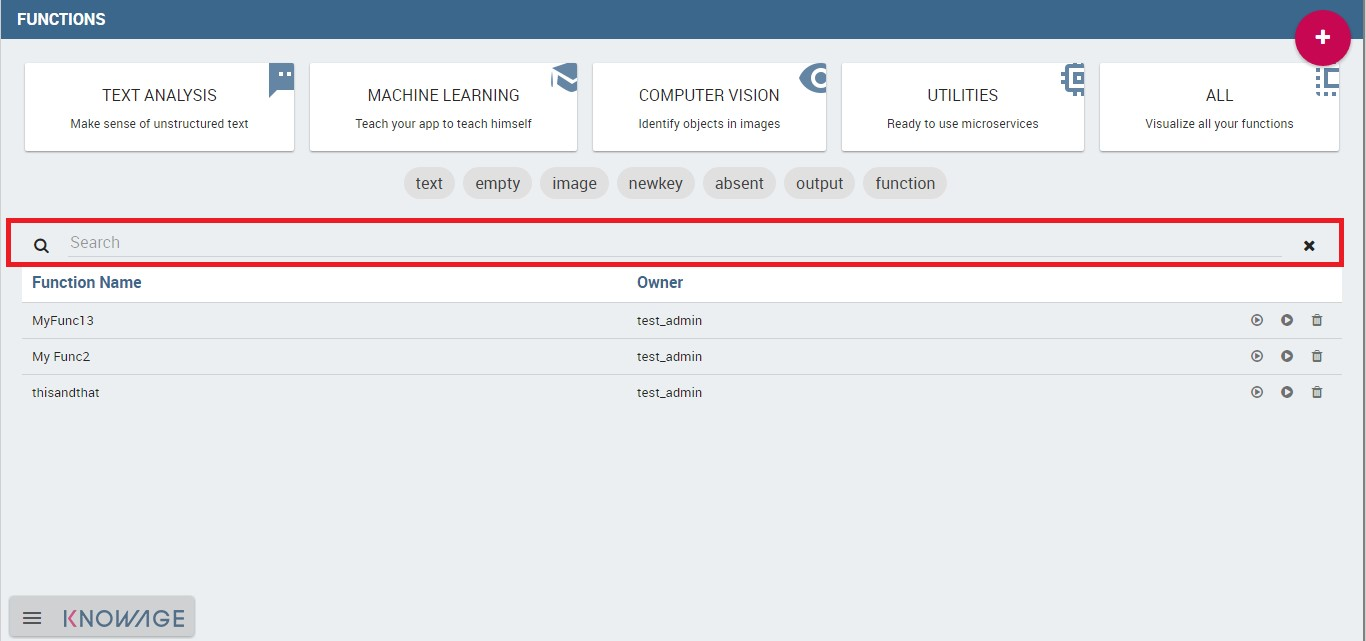
Search box to look for a function.¶
We suppose here to select one category, which means to click on the category box, in order to be able to analyse the functions belonging to it.
Note that the underlined part in figure below contains a list of tags. These help to focus on the subjects and therefore functions associated to that category. Vice versa when all functions are shown, all tags are shown as well and they can be used to pick up functions related to that subject.
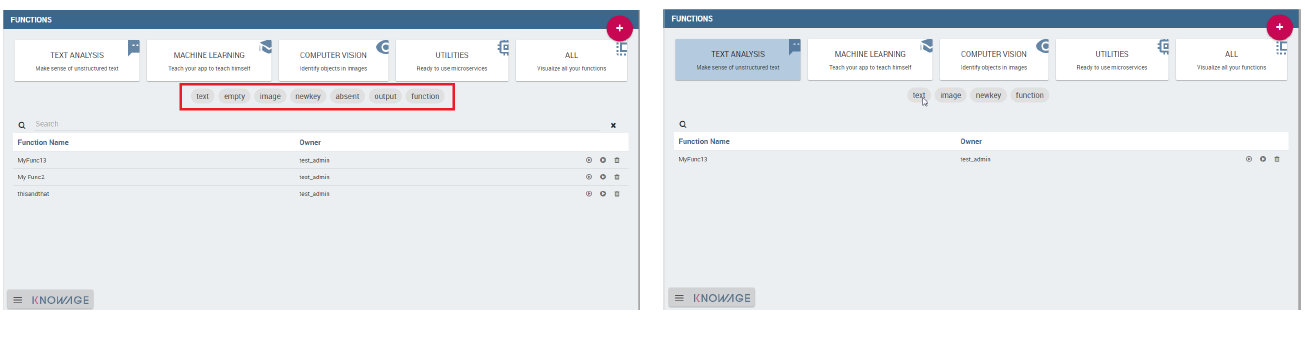
Using tags and categories to look for functions.¶
A preview of the function can be executed using the icon  which opens a dialog in which you can select and configure a dataset among the available ones in order to test the function. Use the icon
which opens a dialog in which you can select and configure a dataset among the available ones in order to test the function. Use the icon  for deleting the function. Functions cannot be deleted if they are used inside one or more documents.
for deleting the function. Functions cannot be deleted if they are used inside one or more documents.
To create a new function an admin user must click on the “Plus” icon available at the right top corner of the page. The action opens the interface shown below. Here you have four tabs that we describe shortly in the following subsections.
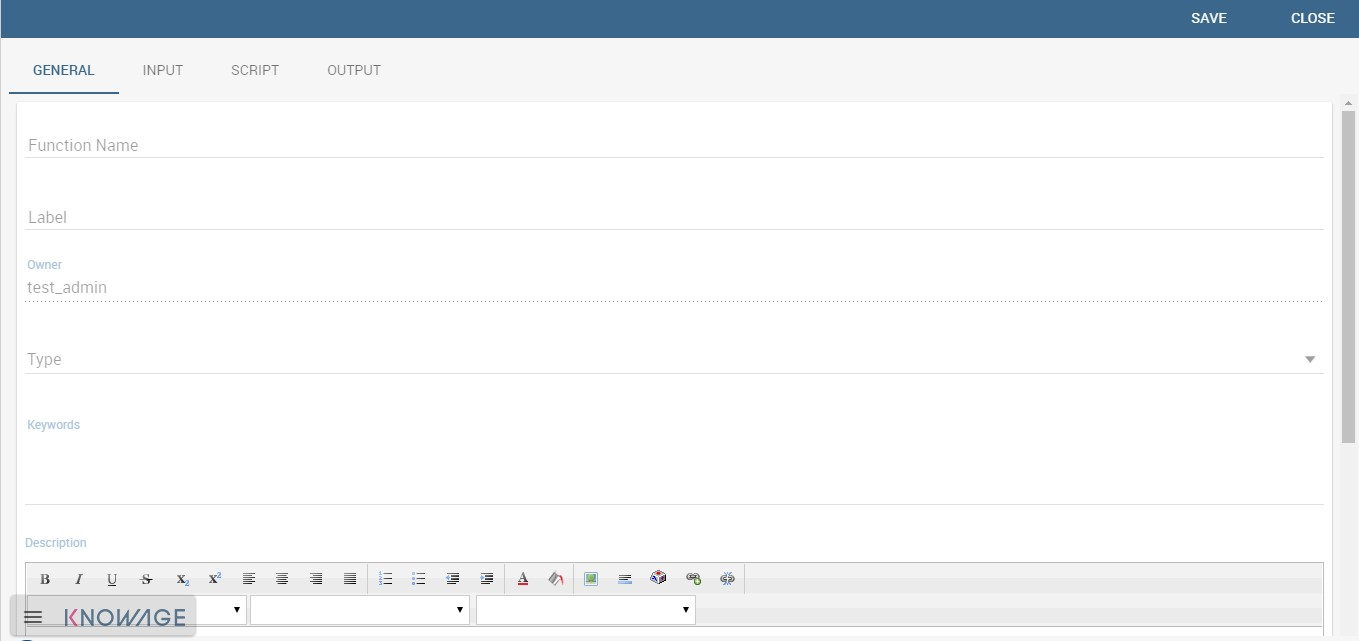
Creating a new function.¶
The General tab¶
In this tab the user gives the general information about the function as the figure above shows. The admin user must type: the name of the function, the label with which it is identified uniquely (remember to use only numbers or letters and do not leave spaces between them). The keywords are were tags are defined. The Description is where the user can insert a text or images to be shown when the function is being configured inside documents. In the Benchmarks field users can insert information about the function performances.
The Input tab¶
As shown in the following figure, the function admits two kinds of input: columns and variables.
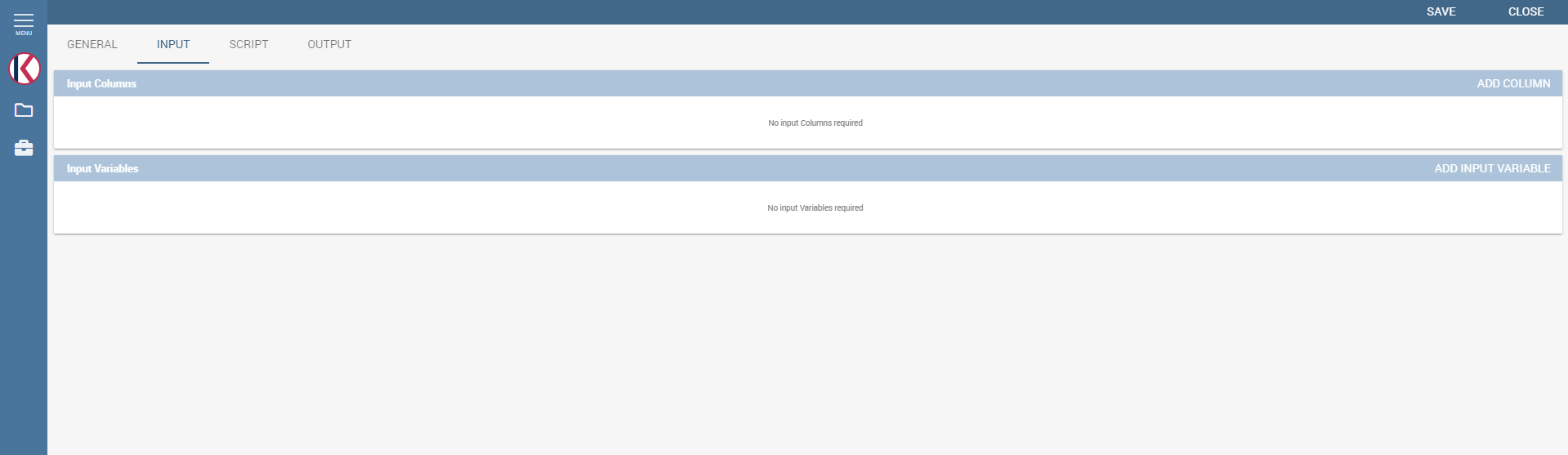
Input tab.¶
In the “Column” instance the function takes input columns that will be referenced inside the script. These columns are generic, the user must only specify their type and the name he later wants to use inside the script to access that specific column.
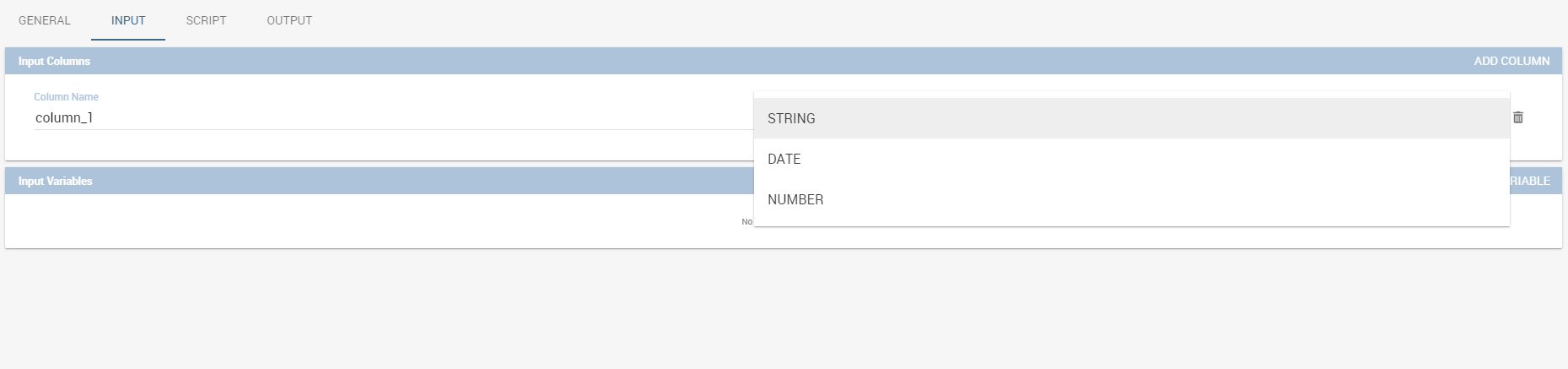
The dataset input of the function settings.¶
In the “Variable” case, the user must insert one or more variables and match them with values using the dedicated area.

The variable input of the function settings.¶
The Script tab¶
The script tab is where an expert user defines the function through the usage of datamining languages (such as Python), as shown in Figure below.
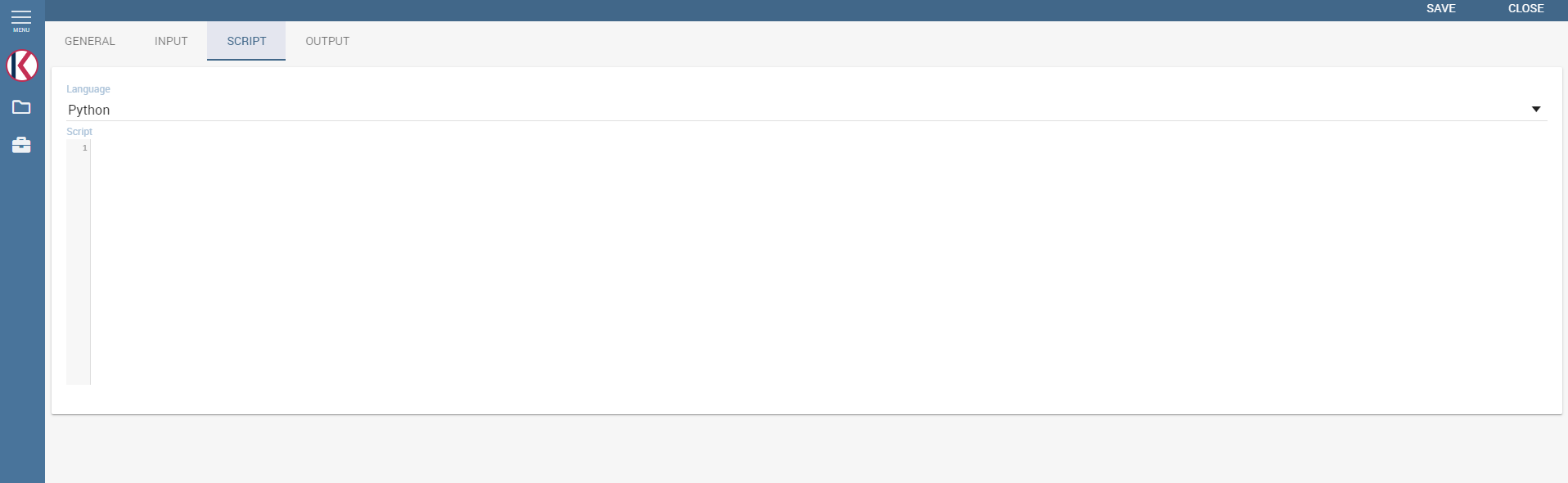
The script tab.¶
Inside the script users will have at their disposal a read-only pandas.Series variable for each column defined in the input tab. To reference one specific column users must use the placeholder ${column_name}. Input variables will be accessible with the same syntax.
1 ${column_name}
2 ${variable_name}
Warning
Input variables are read only
If you want to manipulate them you should first make a local copy and work on it.
The script will have to produce as output one or more pandas.Series variables, and will store them inside the corresponding output placeholders. The following is an example of function template.
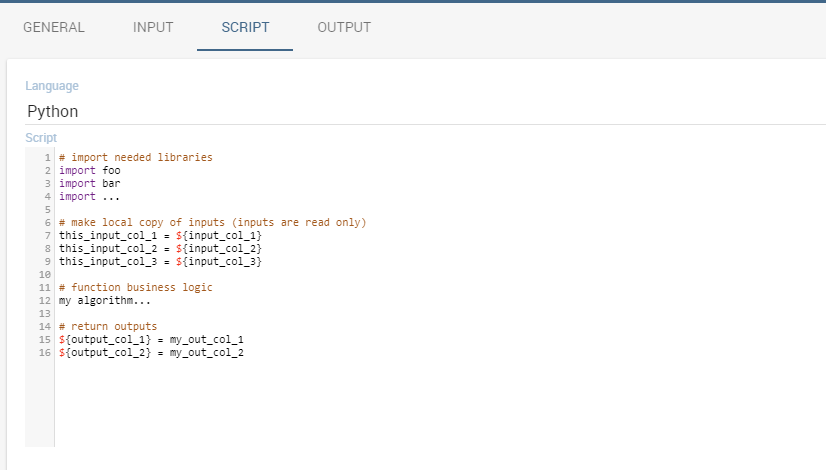
Function template example.¶
The Output tab¶
Finally it is important to define what kind of outputs the function has produced, according to the script generated in the previous tab. Using the “Output“ tab shown below, you must specify:
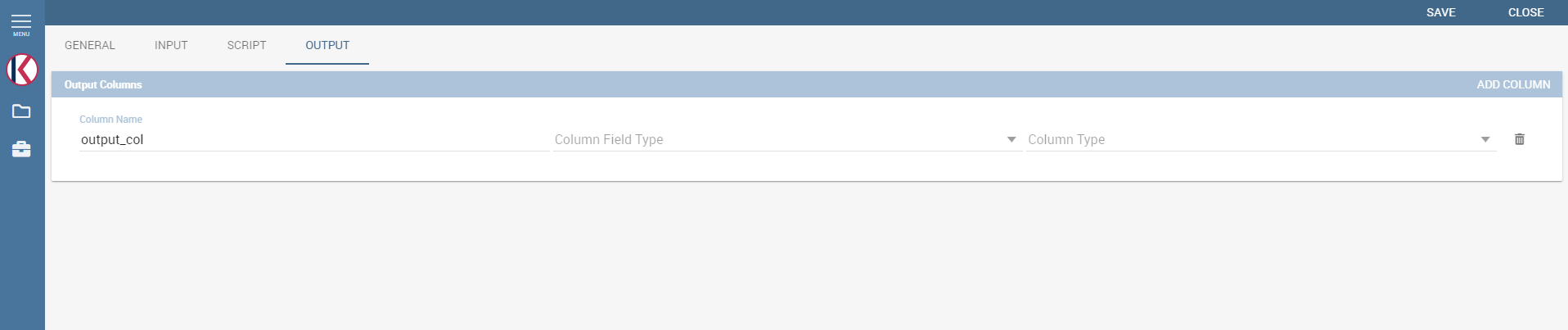
Output tab.¶
Field Type: it can be ATTRIBUTE or MEASURE, and defines how the column will behave inside documents;
Type: it depends on the selected Field Type, it can be String, Number (float) or Date;
Engine description¶
The Catalog Function features leverage on the Python Engine. To understand how to install and configure it, please refer to the Installation Manual
Use a function inside documents¶
Now that functions have been created, they must be used inside documents. In this section we will go through all the steps that allow users to execute a function with a specific dataset. This works both for the function preview and for the function used inside cockpits. Depending on the scenario, you will have two different dialogs. When you are previewing the output of a function, you need to select the dataset you want to use to perform the preview. Therefore on the left card you will be able to select a dataset among the available ones. If the dataset has parameters you will be asked to insert values.
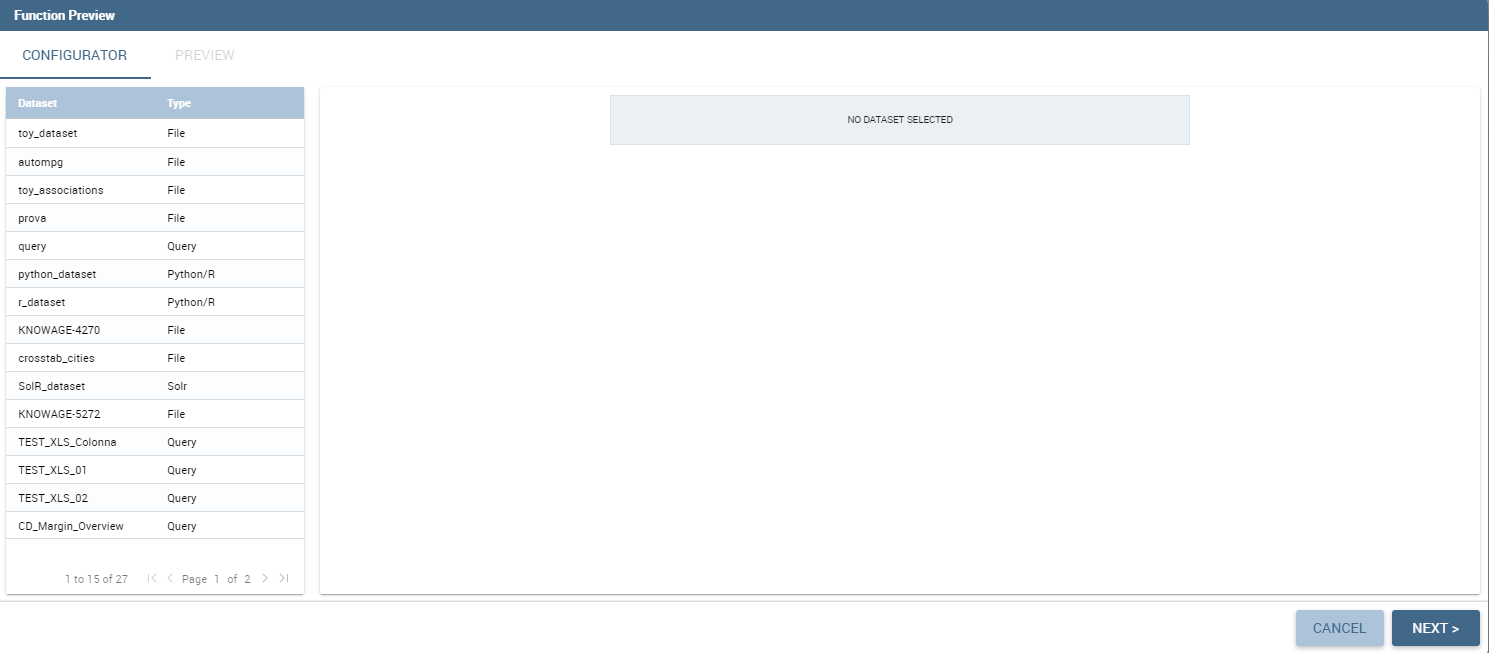
Preview interface.¶
Instead, when you are creating a new widget that uses a function, you will need to click on the Use function button to access the configurator.
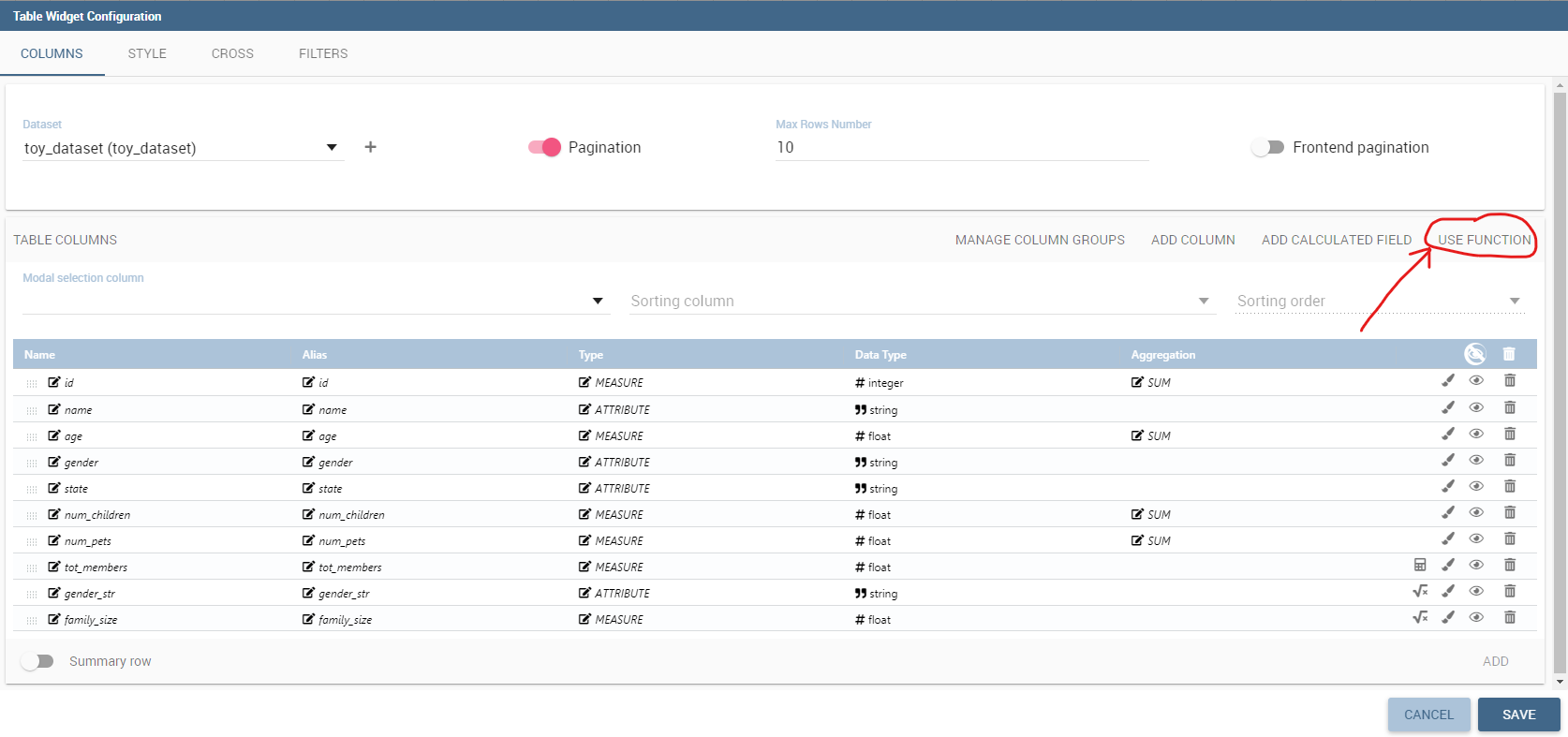
Use a function in a widget.¶
Warning
You cannot use more than one function in the same widget
If you try do so you will get an exception.
Note
Functions are available only in some widgets
Table, crosstable and custom chart.
If you are using a function inside a widget it means that you have already selected the dataset you want to use. Therefore on the left card you will be able to select a function among the available ones.

Catalog function interface in widgets.¶
From this point forward the rest of the configuration is identical for both widget and preview. The first thing that you have to do on the right tab, is bind the input columns of the function with the actual columns coming from the chosen dataset. By doing this you are providing the actual data to the function template. From time to time you can provide different data to the same function just by changing the selected dataset. Depending on this, the same algorithm that is saved inside the function template will work on a different set of data and return different outputs.
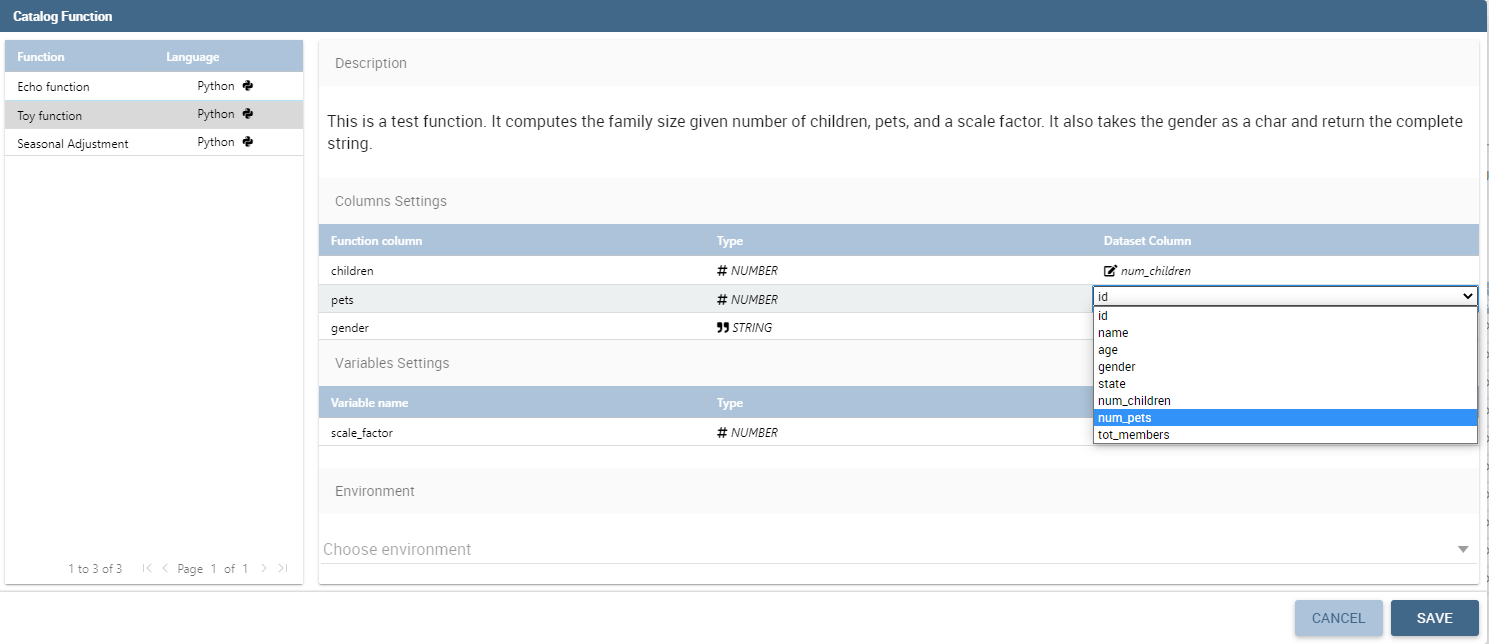
Input columns binding.¶
If you have defined some input variables, you can also set their values.
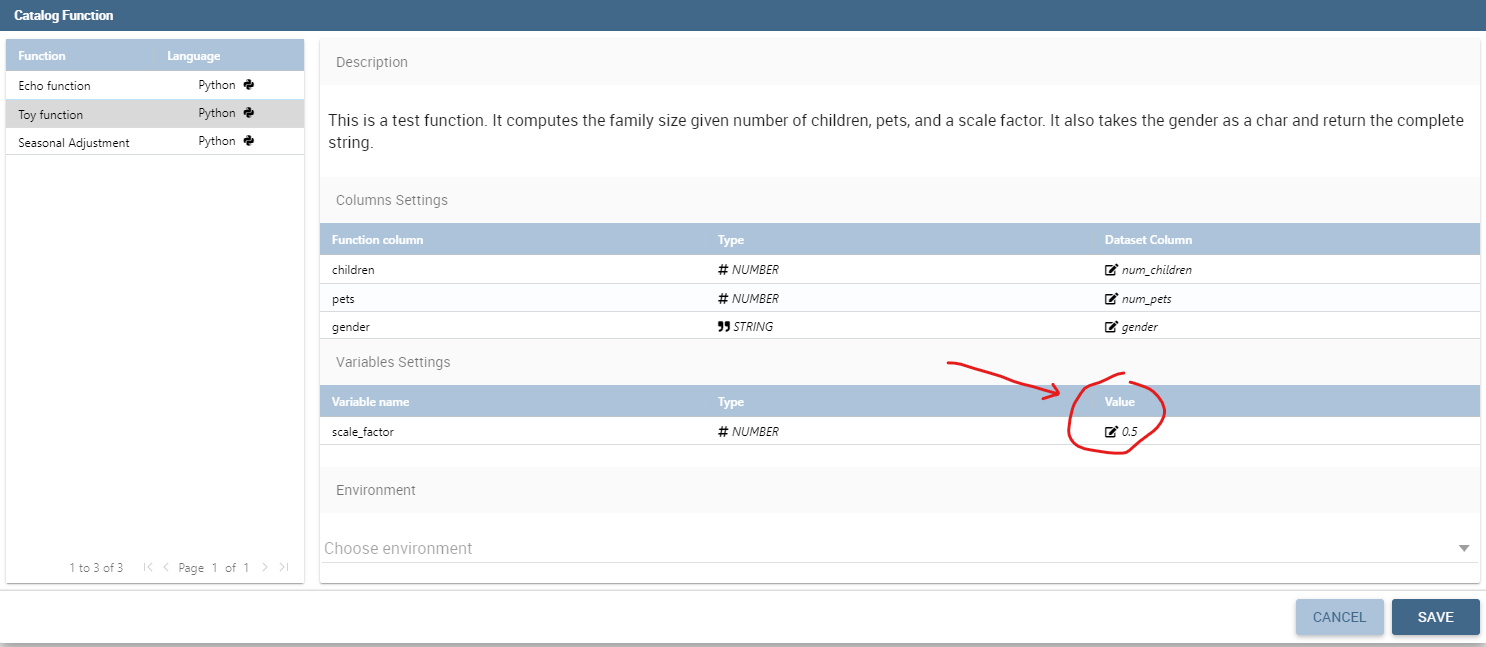
Input variables binding.¶
The last thing you have to choose is the working environment. You can choose the environment among the available ones. To understand better what is an environment, please refer to the Installation Manual
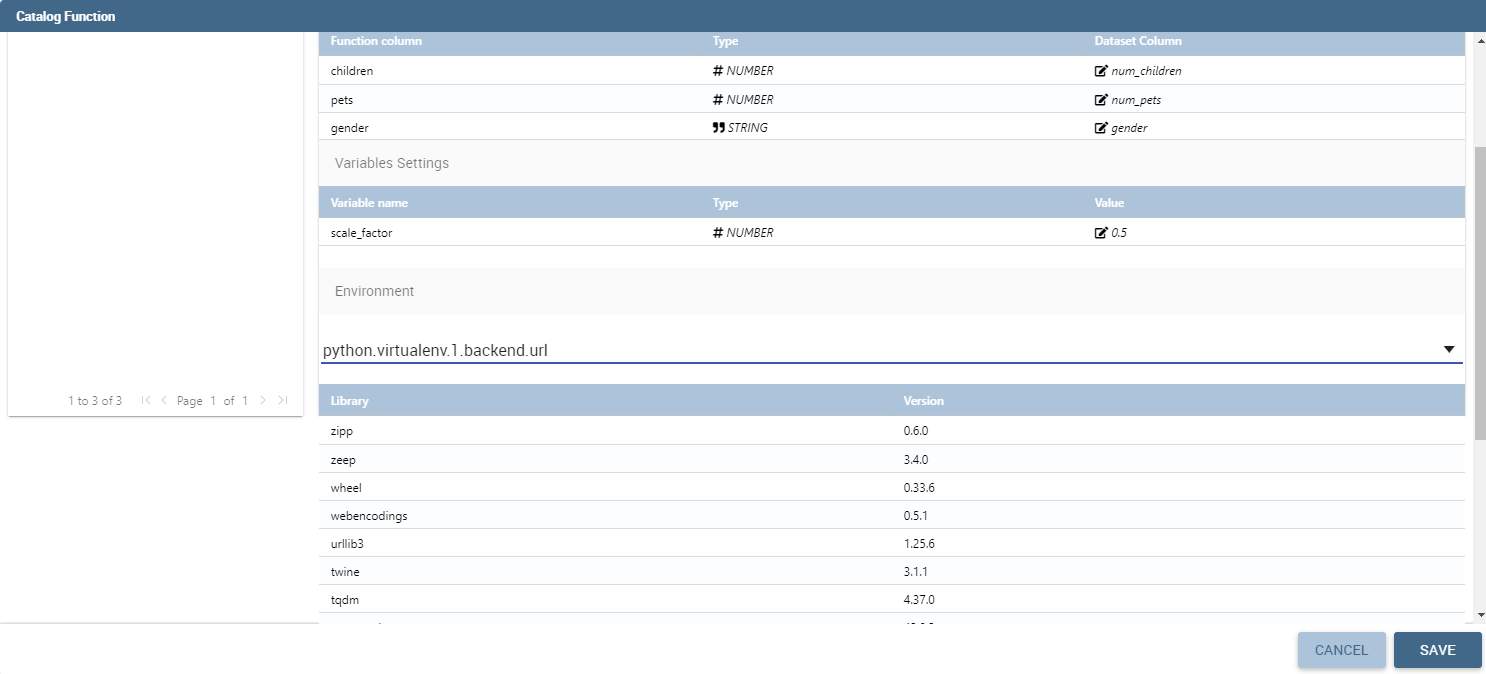
Choose the working environment.¶
After choosing an environment, the list of available libraries installed inside that specific environment appears on screen. You can search or filter libraries and their version in order to find the desired ones, and based on this you can choose the environment that suits your needs the most.
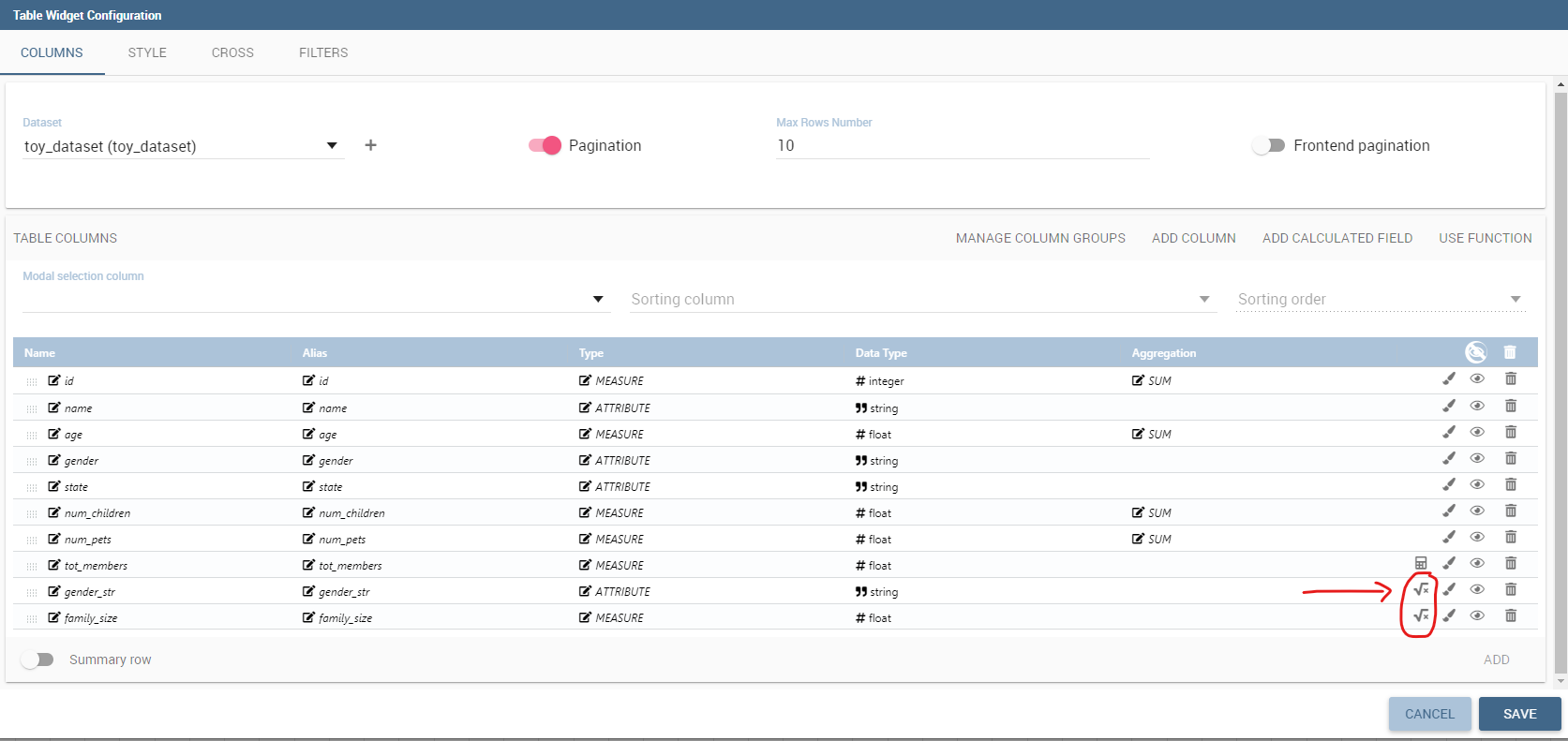
New columns generated by the functions.¶
After saving if you are inside widget configuration you will see that the new output columns generated by the function have been added to the dataset as shown in the figure above. Instead if you were running a preview you will see the output of the dataset execution appearing on screen as shown in the figure below.
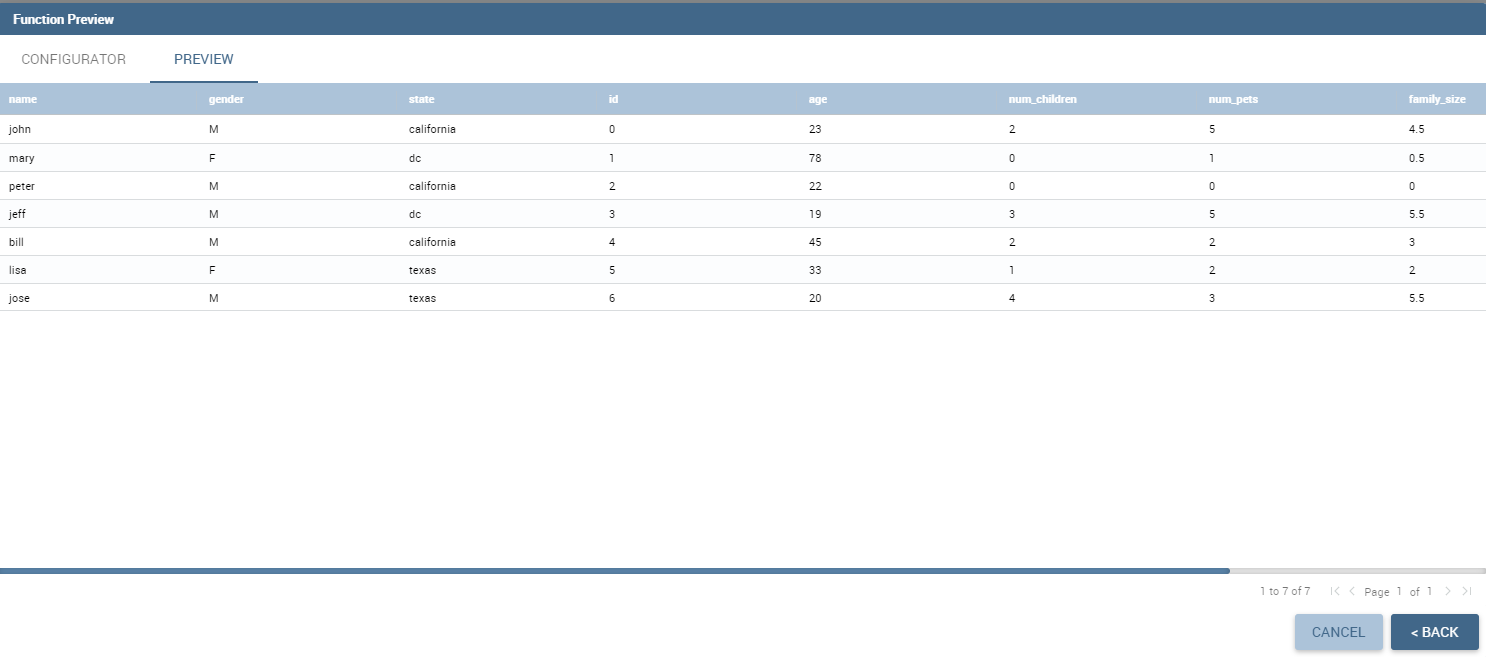
Output of the function preview.¶