Advanced Data Access¶
In this section we suppose to log in as an admin user. In this case the dataset definition is no longer available under My data section. Otherwise the functionality is granted by the Dataset item under the Data Providers section of server menu, as highlighted in figure below. This area offers you the possibility to define datasets among a wide range of types. Moreover you can add parameters, define scope, manage metadata and perform advanced operation on datasets. While the datasets creation and management between user and admin change in favour to the latter, the Models and Federation definitions tabs available in My data section remain identical. For this reason in this chapter we are going to describe only the dataset creation and management.
My first dataset¶
As stated before, you can open the dataset graphical editor by selecting Dataset in Data Provider panel, as shown below.
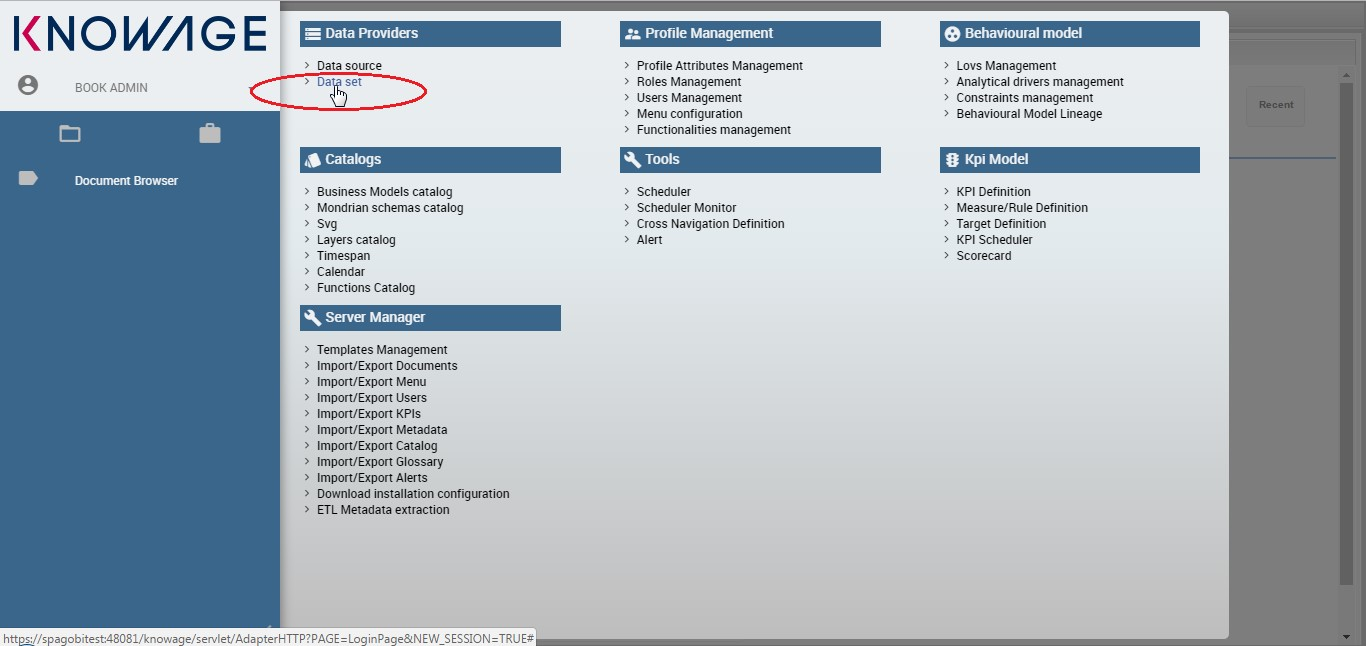
Access data set creation area.¶
A dataset acts as a data provider for analytical documents that’s why many types are supported. Knowage manages several dataset types:
File,
Query,
Java Class,
Script (Groovy, JavaScript, Embedded JavaScript or ECMAScript),
Qbe query over the metamodel,
Custom,
Flat,
Ckan,
Federated,
REST,
Big Data,
Solr,
Python/R.
All types of dataset share some common operations, while others are specific to each of them. The process for defining a dataset inside Knowage follows:
choose a name and a unique label;
choose the type of dataset and the source, depending on the dataset type;
write the code defining the dataset;
associate parameters to the dataset, if any (optional);
apply transformations (optional);
test the dataset and save it.
Some of these steps depend on the specific type of dataset, as we will see.
New dataset creation¶
The dataset graphical editor is divided into two areas: the left side shows the list of all available datasets and the right one shows three tabs, each one corresponding to a specific type of editing operation on dataset.
Each item of the list in the left panel shows the dataset label (i.e., the dataset unique identifier), name and type, as well as the number of documents currently using it. To create a new dataset, click the Add icon  . If your dataset is similar to another existing dataset, you can click the Clone icon
. If your dataset is similar to another existing dataset, you can click the Clone icon  . This will create a copy of the dataset, except for the label that must edit once again. All fields are pre-filled with values from the existing dataset but they can be modified and saved without affecting the original dataset.
. This will create a copy of the dataset, except for the label that must edit once again. All fields are pre-filled with values from the existing dataset but they can be modified and saved without affecting the original dataset.
To remove an existing dataset, click the small dustbin icon  on the corresponding row of the dataset list.
on the corresponding row of the dataset list.
Once you have clicked the Add button, you can fill in the dataset definition form. Each tab in the right panel corresponds to a step of the dataset definition process.
In the Detail tab you define the Name, the Label and an optional Description of the dataset (refer to figure below). There is also a new feature, data set tags. These tags are used for filtering list of data sets and they are placed in the upper left corner of data set catalogue above list of data sets as you can see in the figure below.
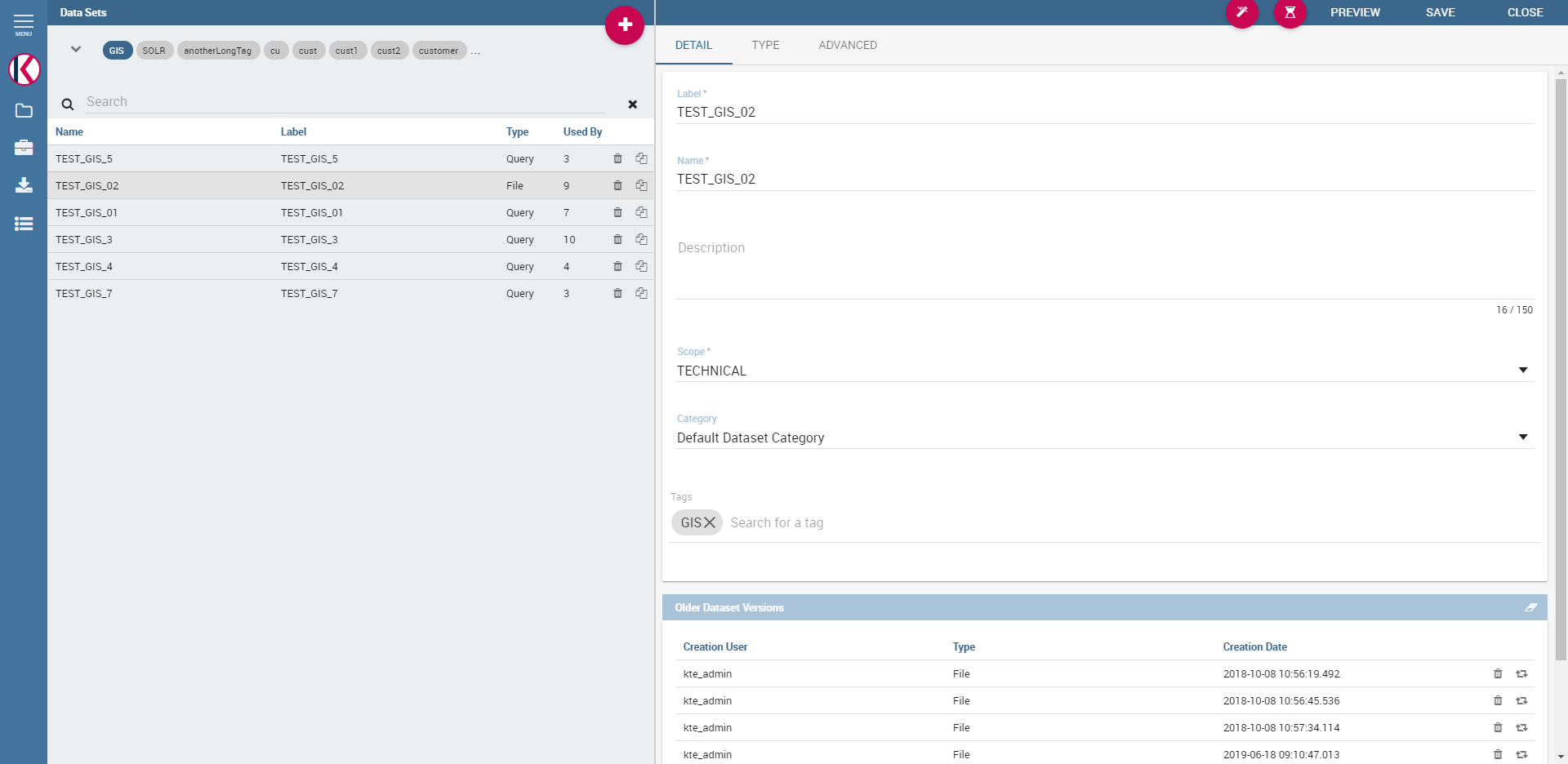
Dataset Panel.¶
By clicking on some of the tags, user is filtering data set list to show only data sets with that tag. In the detail part of data set, user can define tag for that data set by writing the name of the tag in the input field Tags. By clicking on Save button, user saves the new tag and he can see it in the data set tags list.
In the lower part you can see a versioning system for the dataset: Knowage supports dataset versioning, as shown in figure below, therefore, each time you edit and save a dataset, the older version is archived and is still accessible from the lower part of the detail panel.
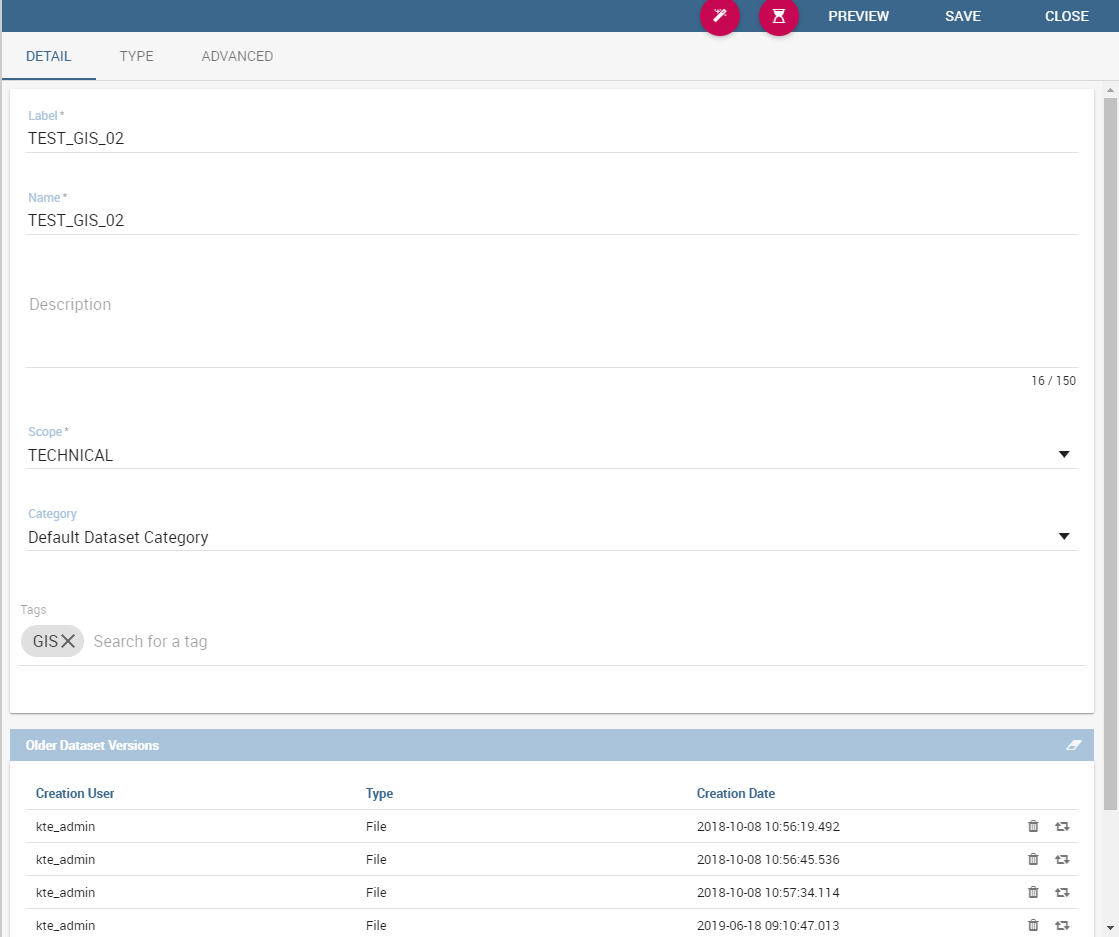
The dataset versioning.¶
The Scope lets you choose between two options, whose combination allows the definition of fine-grained purpose datasets. In Table below all details of possible matching are provided.
Dataset |
Private |
Public |
|---|---|---|
User |
Created from file (CSV, XLS) or from QbE (My Data) for personal use only. |
Dataset created from file (CSV, XLS) or from QbE (My Data) and shared with other users. |
Technical |
Not applicable. |
Dataset created by a BI developer to be used in one or more documents. Not visible to end users. |
Enterprise |
Not applicable. |
Dataset of any type created by a technical user and certified by a trusted entity within the organization, and made available to all end users for reuse. |
You can also specify the Category of the dataset. This field is not mandatory but it can be used to categorize datasets in your BI project, so that you can easily recover them when performing searches.
In the Type tab you can define the type of dataset: here you have to write the code or upload an XLS file or call for a web service accordingly to the dataset type and add parameters to it, if any. An example is shown below.
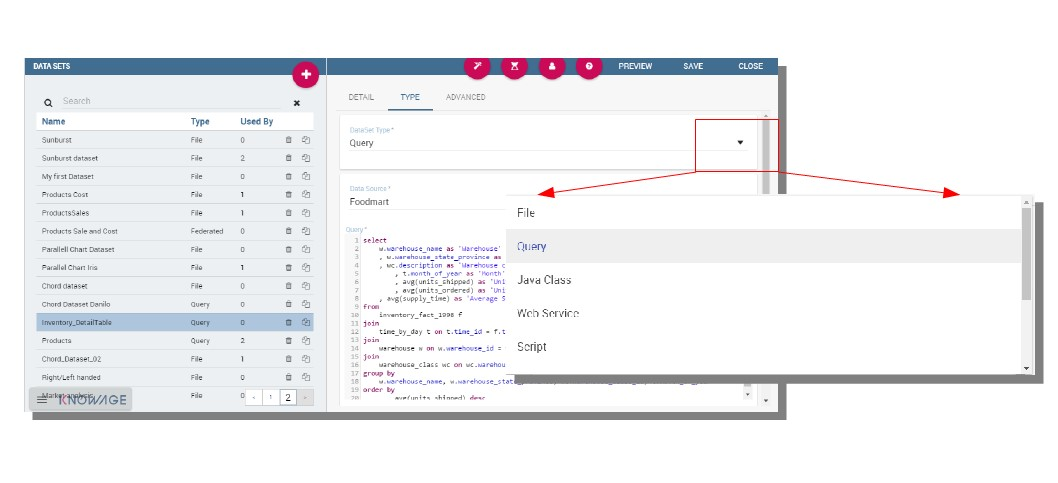
The dataset type definition.¶
In the Advanced tab, shown in figure below, you can apply the pivoting transformation to the dataset results if needed or decide to persist the dataset.
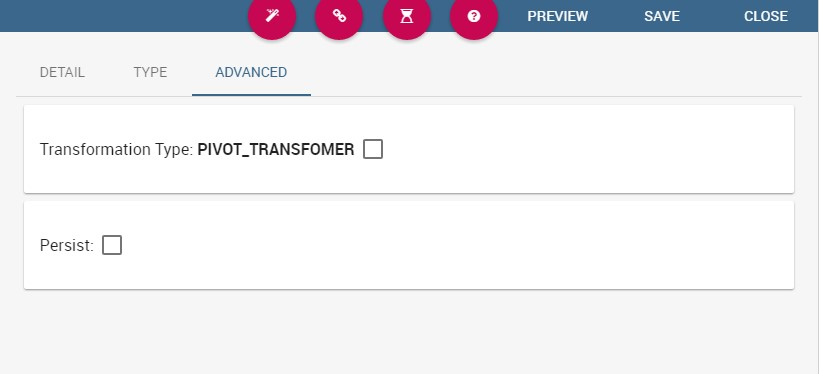
The dataset transformation tab.¶
Once all those settings have been performed you can see a preview of the dataset results clicking on the Preview button available on the top right corner of the page. It is recommended to check preview to detect possible errors in the dataset code before associating it to a document.
Note that the metadata can be manage by clicking on the icon  and use the same criterion described in Dataset paragraph. Otherwise use the icon
and use the same criterion described in Dataset paragraph. Otherwise use the icon  to save without associating any metadata.
to save without associating any metadata.
Let us describe more deeply each type of dataset.
File Dataset¶
A dataset of type File, see the following figure, reads data from an XLS or CSV file. To define a File Dataset select the File type, then upload the file by browsing in your personal folders and set the proper options for parsing it.
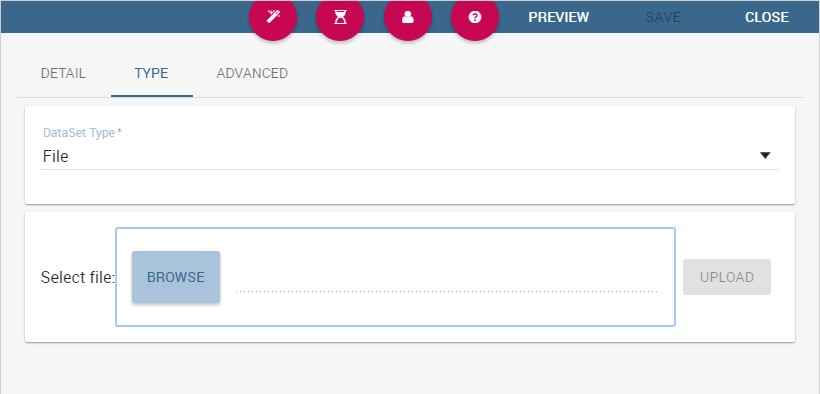
File Dataset.¶
Once you have uploaded the file, you can check and define the metadata (measure or attribute) of each column.
Query Dataset¶
Selecting the query option requires the BI developer to write an SQL statement to retrieve data.
The SQL dialect depends on the chosen data source. The SQL text must be written in the Query text area. Look at SQL query example.
1 SELECT p.media_type as MEDIA, sum(s.store_sales) as SALES
2 FROM sales_fact_1998 s
3 JOIN promotion p on s.promotion_id=p.promotion_id
4 GROUP BY p.media_type
It is also possible to dynamically change the original text of the query at runtime. This can be done by defining a script (Groovy or JavaScript) and associating it to the query. Click on the Edit Script button (see next figure) and the script editor will open. Here you can write the script. The base query is bounded to the execution context of the script (variable query) together with its parameters (variable parameters) and all the profile attributes of the user that executes the dataset (variable attributes).
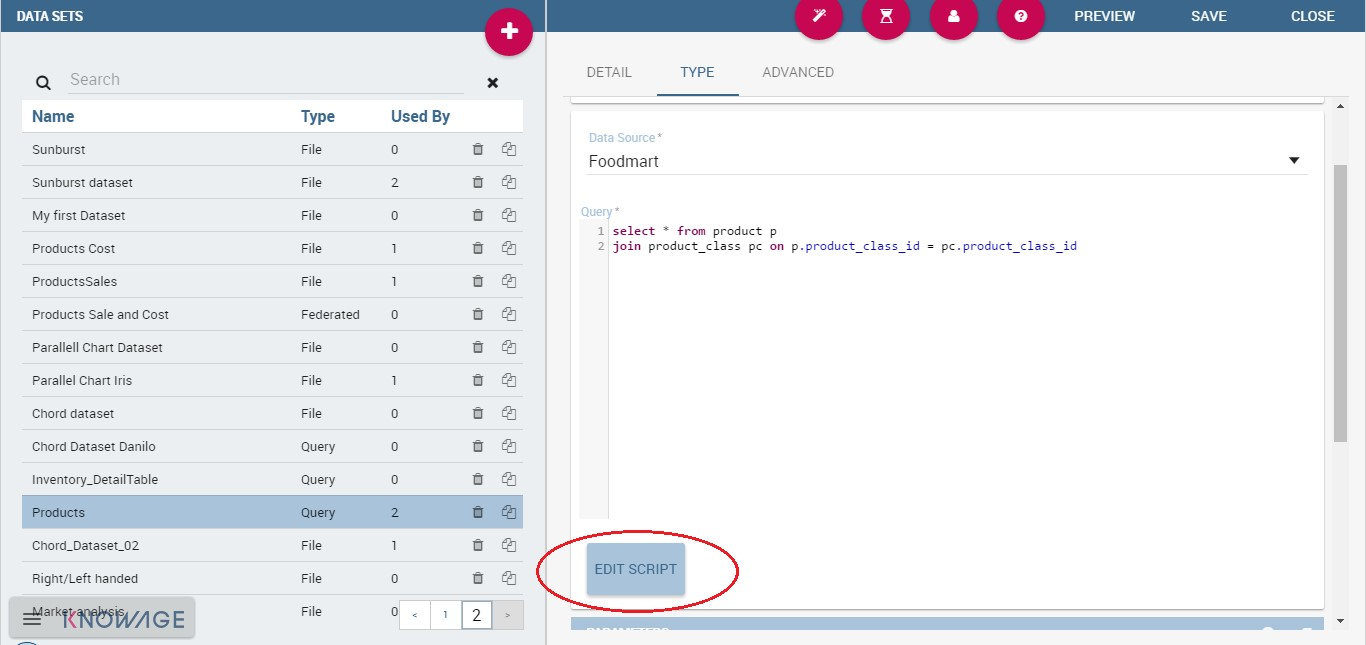
Script editing for dataset.¶
In Code Query dataset’s script example we uses JavaScript to dynamically modify the FROM clause of the original query according to the value of the parameter year selected at runtime by the user.
1 if( parameters.get('year') == 1997 ) { query = query.replace(FROM
2 sales_fact_1998, FROM sales_fact_1997);
3 } else { query = query; // do nothing
4 }
Java Class Dataset¶
Selecting a dataset of Java Class type allows the execution of complex data elaboration implemented by a Java class. The compiled class must be available at \webapps\ KnowageWEB-INF\ classes with the proper package. The class defined by the developer must implement the interface it.eng.spagobi.tools.dataset.bo.IJavaClassDataSet and the methods implemented are:
public String getValues(Map profile, Map parameters). This method provides the result set of the dataset using profile attributes and parameters. The String to return must be the XML result set representation of type:
1 <ROWS>
2 <ROW value="value1" />
3 <ROW value="value2" />
4 </ROWS>
public List getNamesOfProfileAttributeRequired(). This method provides the names of profile attributes used by this dataset implementation class. This is a utility method, used during dataset execution.
Script¶
If you select this option, the results of the dataset will be produced by a script. Therefore, the developer should write a script returning an XML string containing a list of values with the syntax shown below.
1 <ROWS>
2 <ROW value="value1" />
3 <ROW value="value2" />
4 </ROWS>
If the script returns a single value, this will be automatically encoded in the XML format above. The script must be written using Groovy or Javascript language. Knowage already provides some Groovy and JavaScript functions returning the value of a single or multi-value profile attribute. These functions are explained in the information window that can be opened from the Dataset Type tab. New custom functions can be added in predefinedGroovyScript.groovy and predefinedJavascript.js files contained in the KnowageUtils.jar file.
QbE¶
Important
Enterprise Edition
If you purchased Knowage EE, this feature is available only in KnowageBD and KnowageSI
The QbE dataset type option allows the definition of dataset results based on a query defined over a metamodel. To define a QbE dataset you need to select the Data Source and Datamart that you want to use. Once chosen your datamart you can click the lookup button of the Open QbE field and a pop up window will appear showing a QbE interface where you can define your query. Once saved, you can check the generated query thanks to the View QbE Query.
All these features are exhibited below.
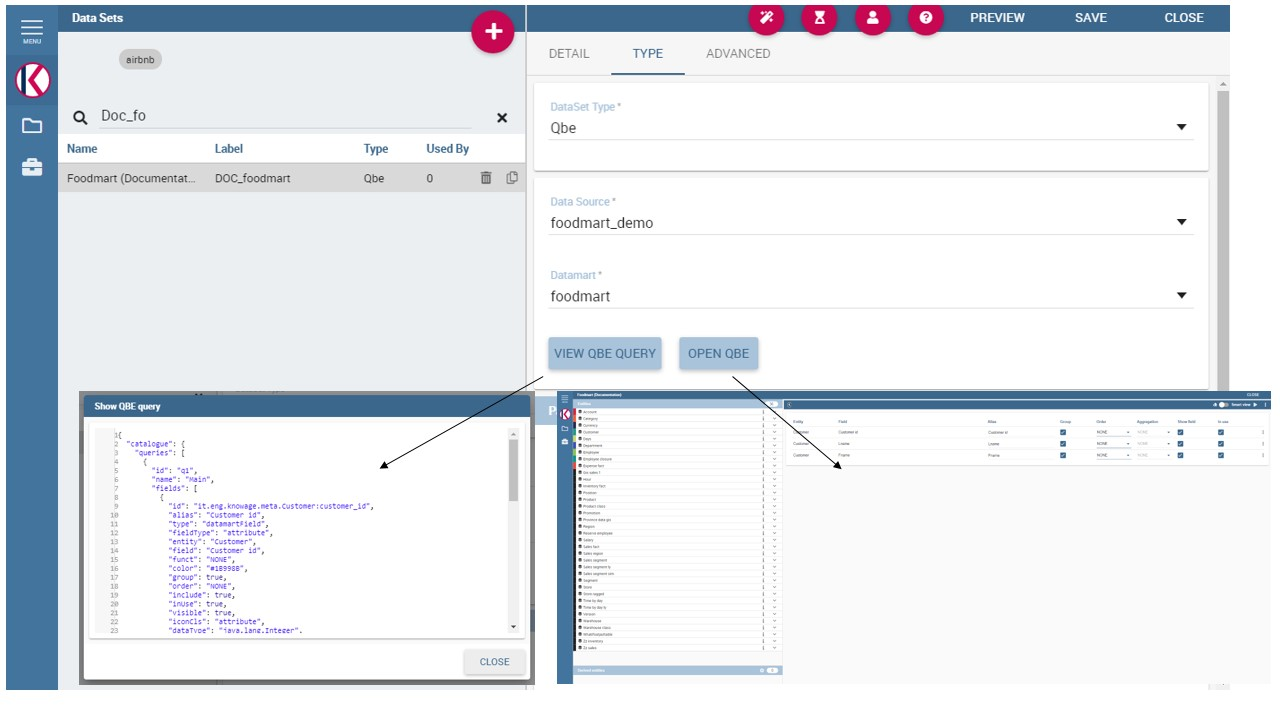
QbE Dataset.¶
Custom Dataset¶
Selecting a Custom dataset type allows the developer to execute complex data elaboration by a custom Java dataset implementation. There are two options:
implement the
it.eng.spagobi.tools.dataset.bo.IDataSetinterface;extend the
it.eng.spagobi.tools.dataset.bo.AbstractCustomDataSetclass.
The methods executing the dataset that must be implemented are:
void loadData();
void loadData(int offset, int fetchSize, int maxResults);
Using the AbstractCustomDataset class allows the developer to access predefined utility methods, such as:
public void setParamsMap(Map paramsMap);
public IDataSetTableDescriptor createTemporaryTable (String tableName, Connection connection);
public IDataStore decode(IDataStore datastore);
private void substituteCodeWithDescriptions(IDataStore datastore, Map<String, List<String>> codes, Map<String, List<String>> descriptions);
private Map<String, List<String>> getCodes(IDataStore datastore).
The full class name (package included) must be set on the Java class name field, while it is possible to add custom attributes for dataset execution and retrieve them via the following method of the IDataSet interface: Map getProperties().
Flat Dataset¶
A flat dataset allows the retrieval of an entire table from a data source. In other words, it replaces a dummy query like select * from sales by automatically retrieving all rows in a table. To create a flat dataset, simply enter the table and the data source name, as shown below.
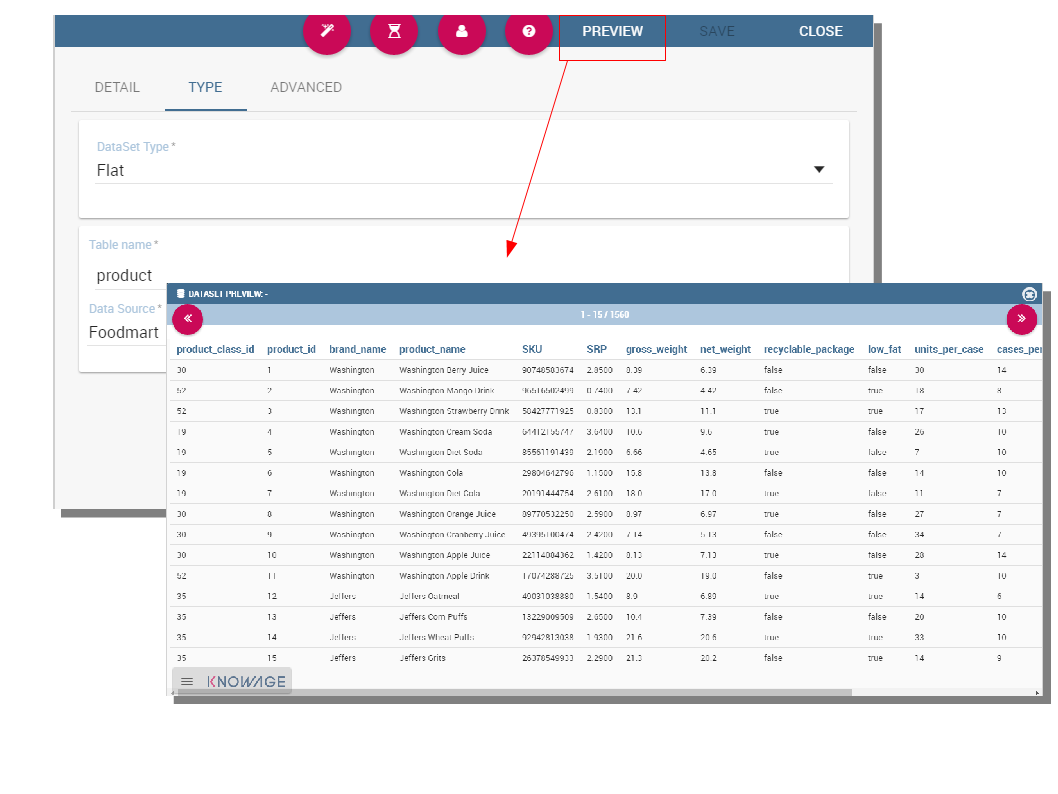
Flat Dataset.¶
Ckan¶
Important
Enterprise Edition
If you purchased Knowage EE, this feature is available only in KnowageBD and KnowageSI
A Ckan dataset let you use open data as resource. You have to fill all the settings fields properly to let the dataset work successfully. Let’s have a look on them:
File Type: this field specifies the type of the file you want to import. Allowed ones are: CSV or XML;
Delimiter Character: Here you have to insert the delimiter used in the file. Allowed values are: , ; \t |
Quote Character: Allowed values for this field are: “ or ”;
Encoding: Here you have to specify the encoding typology used. Allowed values are: UTF-8, UTF-16, windows-1252 , ASCII or ISO-8859-1;
Skip rows: the number inserted stands for the rows not to be imported;
Limit rows: it is the maximum number of rows to be imported. If you leave it blank all rows are uploaded;
XLS numbers: it is the number of sheets to be imported;
CKAN ID : here you have to insert the ID of the resource you are interested in. Look for it among the additional information in Ckan dataset webpage.
CKAN url: it is the direct link to download the resources available on Ckan dataset webpage.
We marked with the * symbol the mandatory fields. We suggest to do a preview of your dataset before saving it to be sure everything have been correctly configured.
Federated¶
Important
Enterprise Edition
If you purchased Knowage EE, this feature is available only in KnowageBD and KnowageSI
In this area you can only manage metadata, visibility and perform the advanced operation we are going to describe at the end of this section.
Instead, the creation of Federated done can be accessed from My data BI functionality under Federatation Definitions.
Rest¶
The REST dataset enables Knowage to retrieve data from external REST services. The developer of the dataset is free to define the body, method, headers and parameters of the request; then he has to specify how to read data from the service response using JSON Path expressions (at the moment no other ways to read data is available, therefore the REST service is presumed to return data in JSON format).
Let’s make as example in order to understand how it works. Suppose an external REST service providing data from sensors, we want to retrieve values from prosumers electricity meters, a prosumer being a producer/consumer of electricity, and that the request body should be something like:
1{ "entities": [ {
2 "isPattern": "true",
3 "id": ".*",
4 "type":"Meter"
5 } ]
6}
while querying for Meter entities, and that the JSON response is something like:
1{
2 "contextResponses": [
3 {
4 "contextElement": {
5 "id": "pros6_Meter",
6 "type": "Meter",
7 "isPattern": "false",
8 "attributes": [
9 {
10 "name": "atTime",
11 "type": "timestamp",
12 "value": "2015-07-21T14:49:46.968+0200"
13 },
14 {
15 "name": "downstreamActivePower",
16 "type": "double",
17 "value": "3.8"
18 },
19 {
20 "name": "prosumerId",
21 "type": "string",
22 "value": "pros3"
23 },
24 {
25 "name": "unitOfMeasurement",
26 "type": "string",
27 "value": "kW"
28 },
29 {
30 "name": "upstreamActivePower",
31 "type": "double",
32 "value": "3.97"
33 }
34 ]
35 },
36 "statusCode": {
37 "reasonPhrase": "OK",
38 "code": "200"
39 }
40 },
41 {
42 "contextElement": {
43 "id": "pros5_Meter",
44 "type": "Meter",
45 "isPattern": "false",
46 "attributes": [
47 {
48 "name": "atTime",
49 "type": "timestamp",
50 "value": "2015-08-09T20:29:45.698+0200"
51 },
52 {
53 "name": "downstreamActivePower",
54 "type": "double",
55 "value": "1.8"
56 },
57 {
58 "name": "prosumerId",
59 "type": "string",
60 "value": "pros5"
61 },
62 {
63 "name": "unitOfMeasurement",
64 "type": "string",
65 "value": "kW"
66 },
67 {
68 "name": "upstreamActivePower",
69 "type": "double",
70 "value": "0"
71 }
72 ]
73 },
74 "statusCode": {
75 "reasonPhrase": "OK",
76 "code": "200"
77 }
78 }
79 ]
80 }
In this example we have two Context Elements with the following attributes:
atTime ;
downstreamActivePower;
prosumerId;
unitOfMeasurement;
upstreamActivePower.
Let’s see how to define a Knowage dataset:
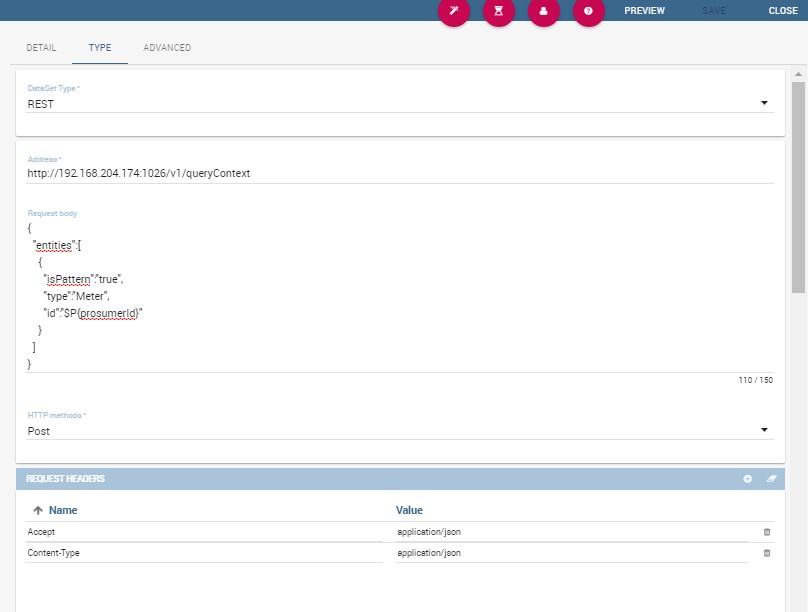
REST dataset interface.¶
We specified
the URL of the REST service;
the request body;
the request headers (in this example we ask the service for JSON data);
the HTTP method;
the JSONPath to retrieve the items (see below), i.e. the JSONPath where the items are stored;
the JSONPaths to retrieve the attributes (see below), i.e. the JSONPaths useful to retrieve the attributes of the items we are looking for; those paths are relative to the “JSON Path items”;
offset, fetch size and max results parameters, in case the REST service has pagination.
Once followed the steps above the user obtains upstream/downstream active power for each prosumer.
NGSI checkbox is specific for NGSI REST calls: it permits easy the job when querying the Orion Context Broker (https://github.com/telefonicaid/fiware-orion) and to omit some of the REST fields (since the JSON format from NGSI specifications is fixed): you don’t need to specify headers, JSONPath items, JSONPath attributes (all available attributes are fetched) and pagination parameters (offset and fetch size).
When checking the Use directly JSON attributes checkbox, yon can skip the definition of the JSONPath attributes, since the JSON structure is presumed to be fixed as in the following example:
1{
2 "contextResponses": [
3 {
4 "prosumerId":"pros1",
5 "downstreamActivePower":3.1,
6 "upstreamActivePower":0.0
7 },{
8 "prosumerId":"pros2",
9 "downstreamActivePower":0.5,
10 "upstreamActivePower":2.4
11 }
12 ]
13}
Then it will be enough to define only the JSON Path Items and check Use directly JSON Attributes without defining the attributes; the attributes will be retrieved automatically from the JSON object.
In the above examples, the JSON Path Items will be $.contextResponses[:sub:`\*`] and the dataset result will look like:
prosumerId |
downstreamActivePower |
upstreamActivePower |
|---|---|---|
pros1 |
3.1 |
0.0 |
pros2 |
0.5 |
2.4 |
The REST dataset permits usage of profile attributes and parameters using the same syntax as for other dataset types: $<profile attribute> and $P<parameter>. You can use both of them as placeholders in every field: most likely you need to use them in REST service URL or on the request body. As an example, suppose you want to retrieve the value of just one prosumer that is specified by the prosumerId parameter, you have to set the request body as:
1{
2 "entities":[
3 {
4 "isPattern":"true",
5 "type":"Meter",
6 "id":"$P{prosumerId}"
7 }
8 ]
9}
Python/R¶
The Python/R dataset enables users to create a dataset by writing a Python or R script that directly retrieves data. The developer of the dataset is free to write code which has to produce a dataframe variable as output (for Python scripts we refer to pandas dataframes). This variable will contain data that Knowage will later convert into its own format.
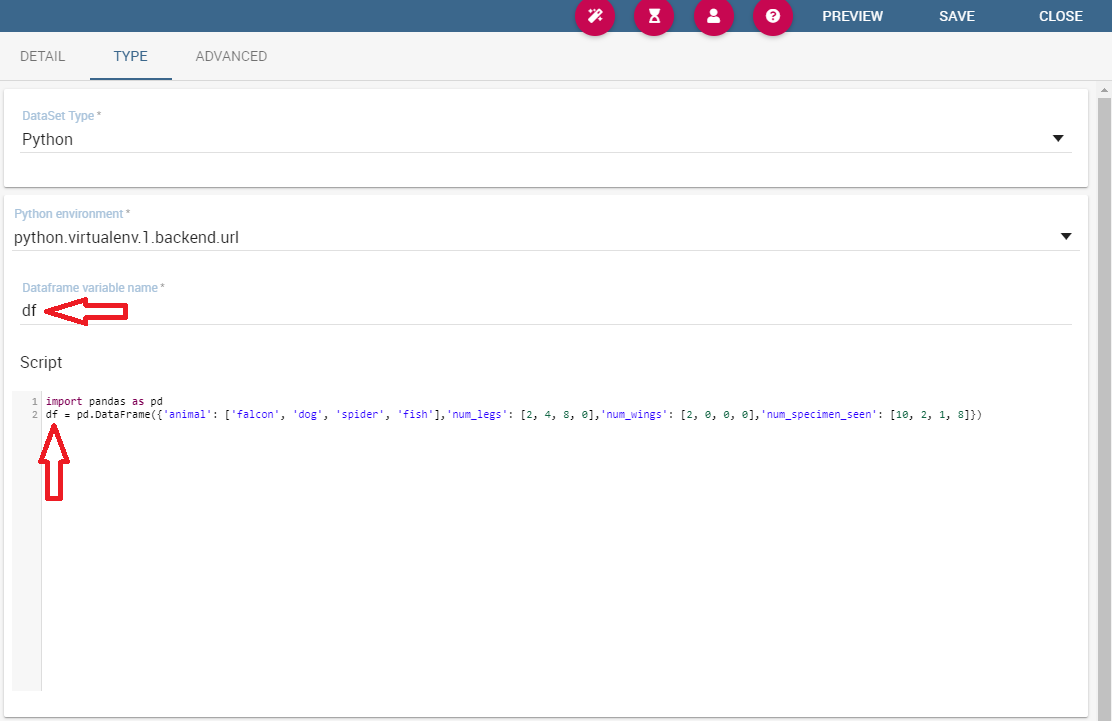
Python/R dataset interface.¶
As shown in the picture in the field Dataframe variable name the developer has to specify the name of the variable in which the final output of the script is stored in the form of a dataframe.
In the field Python environment the user can select a working environment among the available ones defined in the Configuration Management section.
Inside the scripts it is possible to use parameters by the usual syntax $P{}.
Big Data - NoSQL¶
Important
Enterprise Edition
If you purchased Knowage EE, this feature is available only in KnowageBD and KnowagePM
Knowage provides the possibility to define Big Data dataset as well as Big Data datasources. To set these kind of datasets the user just have to select the Query type and insert the code according to the dialect in use (that is accordingly to the datasource dialect).
For example, let’s suppose we defined a Mongo datasource and want to create a dataset upon it. Therefore choose the “Query type” dataset and, as we revealed in advance, choose the correct language: in this case JS instead of SQL. The script must respect some convention, in particular:
the return value of the query must be assigned to a variable with name ”query“. For example
1var query = db.store.find();
if the return value doesn’t come from a query, for example it’s a js variable, than it must be assigned to a variable with name
sbiDatasetfixedResult. The result will be managed by Knowage accordingly to the type of the variable:if it’s a primitive type the resulting dataset contains only a columns with name
resultand value equal to the value of the variablesbiDatasetfixedResult;if it’s an object, the resulting dataset contains a column for each property of the object.
For example, if we consider the query
sbiDatasetfixedResult = {a:2, b:3}the dataset is as shown in Table below.
a |
b |
|---|---|
2 |
3 |
if it’s a list than the columns of the dataset are the union of the properties of all the objects contained in the list.
For istance, let’s consider the query
sbiDatasetfixedResult = [{a:2, b:3},{a:2, c:3}]the dataset is
a |
b |
c |
|---|---|---|
2 |
3 |
|
2 |
3 |
The result of a query in MongoDB can assume different shapes: Cursor, Document, List, fix value. Knowage can manage automatically the result of the query. The algorithm to understand how to manage the result is very simple.
If in the query it finds the variable sbiDatasetfixedResult the result will be managed as described above.
If in the query it finds a findOne the result will be managed as a single document.
If in the query it finds an aggregate the result will be managed as an aggregation.
In the ether cases the result will be managed as a Cursor.
It’s possible to force the behaviour. In particular the result stored in the variable query, will be managed:
as cursor if in the script exist a variable with value
LIST_DOCUMENTS_QUERY. Example:
1 var retVal= "LIST_DOCUMENTS_QUERY“;
a document if in the script exist a variable with value
SINGLE_DOCUMENT_QUERY. Example:
1 var retVal= "SINGLE_DOCUMENT_QUERY”;
Similar techniques can be applied to the other languages. We leave the reader to examine the dialect related to each Big Data datasource.
Note
MongoDB Document size
Remember that MongoDB has a limit of maximum 16MB for the returned document (BSON), so pay attention to that when creating your dataset. For more information check this link: https://docs.mongodb.com/manual/reference/limits/
Solr Dataset¶
A dataset of type Solr, see the following figure, reads data from the popular Search Engine Solr. To define a Solr Dataset select the Solr type, then choose between Document or Facets type.
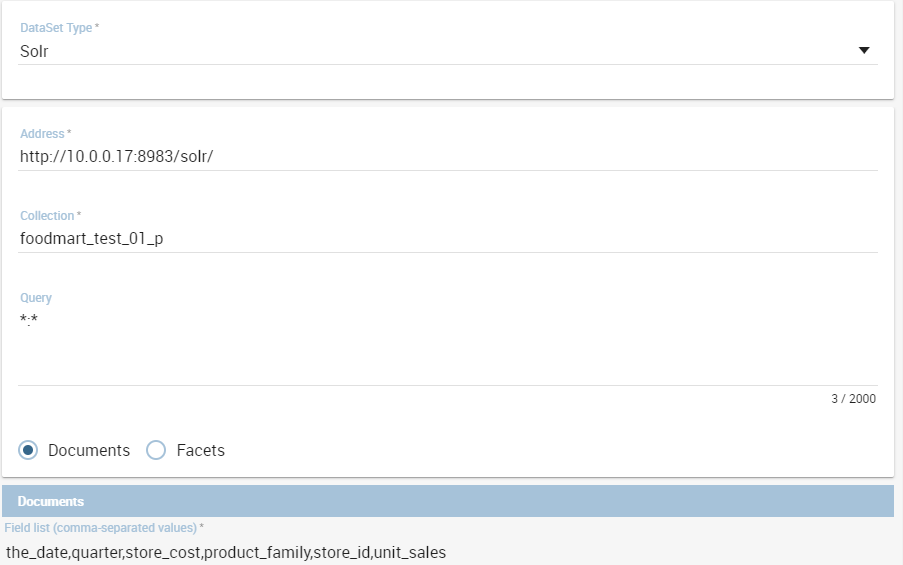
Solr Dataset, Document type selected.¶
The Query field is the Solr query using the Solr standard query syntax. The Collection field is the core, in Solr, the term core is used to refer to a single index and associated transaction log and configuration files (including the solrconfig.xml and Schema files, among others). Your Solr installation can have multiple cores if needed, which allows you to index data with different structures in the same server, and maintain more control over how your data is presented to different audiences. In SolrCloud mode you will be more familiar with the term collection. Behind the scenes a collection consists of one or more cores.
Documents
According to the Solr official documentation, Solr’s basic unit of information is a document, which is a set of data that describes something. A recipe document would contain the ingredients, the instructions, the preparation time, the cooking time, the tools needed, and so on. A document about a person, for example, might contain the person’s name, biography, favorite color, and shoe size. A document about a book could contain the title, author, year of publication, number of pages, and so on.
In the Solr universe, documents are composed of fields (these fields can be put into section document field list), which are more specific pieces of information. Shoe size could be a field. First name and last name could be fields. If you have chosen the type “Documents”, you can add the document fields to the list below called “Documents”.
Request header, if there is the need, it is possible to customize the request header of the post http request, adding optional parameters.
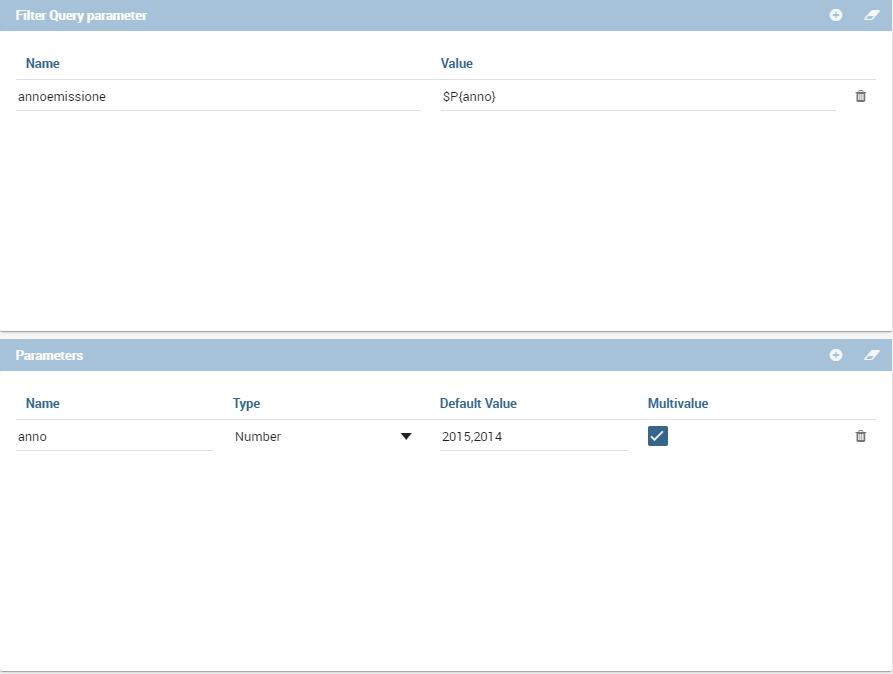
Solr Dataset, Optional fields for filtering parameters.¶
Solr dataset can also use Profile Attributes.
The syntax to include attributes into the dataset text is ${attribute_name}. Profile attributes can be single-value or multivalue.
The filter query parameter is the Solr fq parameter and defines a query that can be used to restrict the superset of documents that can be returned, without influencing score. It can be very useful for speeding up complex queries, since the queries specified with fq are cached independently of the main query. These parameters can be used in combo with document parameters using the P{} notation like the example picture shows.
Fields Mapping
It is important to set field types correctly in order to use a Solr dataset without problems. A field type defines the analysis that will occur on a field when documents are indexed or queries are sent to the index.
A field type definition can include four types of information:
The name of the field type (mandatory). An implementation class name (mandatory). If the field type is a number and it has decimals it must be set as pdouble (not int or string!!). If the field type is TextField, a description of the field analysis for the field type. Field type properties - depending on the implementation class, some properties may be mandatory.
Example: <field name=”REG_T_MP” type=”pdouble” indexed=”true” required=”false” stored=”true” multiValued=”false”/>
Faceting
Faceting is the arrangement of search results into categories based on indexed terms. If you choose Facets you can add the Facet Query. This parameter allows you to specify an arbitrary query in the Lucene default syntax to generate a facet count. The Facet Field is the facet.field parameter and identifies a field that should be treated as a facet. It iterates over each Term in the field and generate a facet count using that Term as the constraint. This parameter can be specified multiple times in a query to select multiple facet fields. The Facet Prefix is the facet.prefix parameter limits the terms on which to facet to those starting with the given string prefix. This does not limit the query in any way, only the facets that would be returned in response to the query.
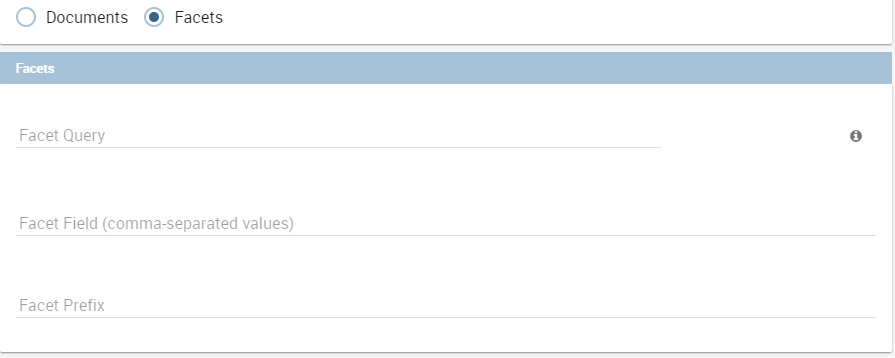
Parameters and profile attributes¶
All dataset types except File and CKAN allow you to add parameters. This means that results can be customized according to the value of one or more parameters at execution time. Parameters can be managed from the Type tab. Two operations are needed to add a parameter to the dataset:
insert the parameter in the actual text of the dataset;
create the parameter in the parameters list below the editor area.
The syntax to add a parameter in the dataset code text is $P{parameter_name}. At dataset execution time, the parameter will be replaced by its actual value.
Warning
Attention to parameters’ names!
If the dataset is used by a Knowage document, then the document parameters’ URL must match the parameter name set in the dataset Type tab, in order for the dataset to be passed correctly.
Any parameter added to your dataset must be added to the parameters list, too. To add a parameter in the list, click the Add button. A new row will be created in the list: double click the name and edit the parameter values. There are three different types of parameters. For each of them the placeholder will be replaced according to a different pattern, as follows:
String: the parameter value will be surrounded with single quotes if not already present.
Number: the parameter value is treated as a number, with no quotes; an exception is thrown if the value passed is not a number.
Raw: the parameter value is treated as a string containing a set of values; single quotes are removed from the containing string, not from the single strings composing it.
Generic: the parameter is simply passed as it is, with no further processing.
In SQL query example with parameters an example is provided, where MediaType is a string parameter.
1SELECT s.customer_id as CUSTOMER
2, sum(s.store_sales) as SALES
3, c.yearly_income as INCOME
4, p.media_type as MEDIA
5FROM sales_fact_1998 s, customer c, promotion p
6WHERE
7s.customer_id=c.customer_id and s.promotion_id=p.promotion_id and
8p.media_type in ($P{MediaType})
9GROUP BY
10s.customer_id,
11c.yearly_income,
12p.media_type
Datasets of type Query and Script can also use profile attributes. Differently from parameters, profile attributes do not need to be explicitly added to the parameter list since they have been defined elsewhere. Clicking the Available Profile Attribute button you can see all profile attributes defined in the behavioural model and choose the one(s) you wish to insert in the dataset query/script text, as shown below.
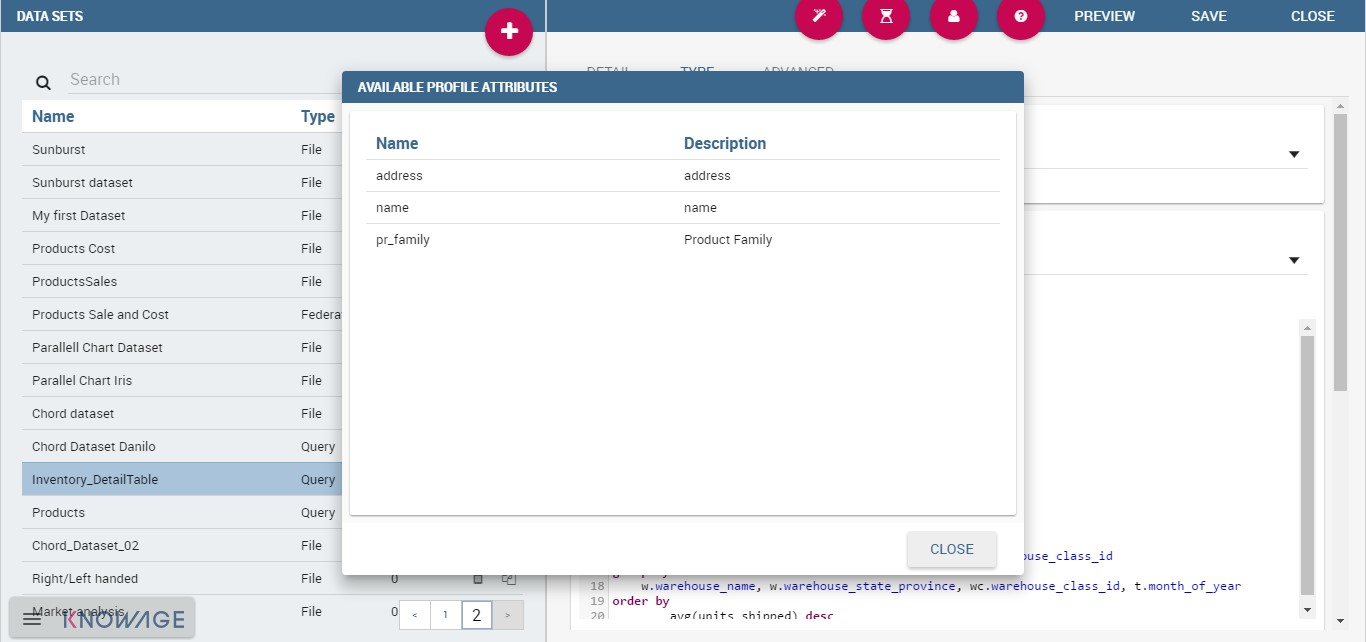
Profile Attributes assignment.¶
The syntax to include attributes into the dataset text is ${attribute_name}. Profile attributes can be single-value or multivalue.
Note
User profile attributes
Each Knowage user is assigned a profile with attributes. The user profile is part of the more general behavioural model, which allows tailored visibility and permissions on Knowage documents and functionalities.
Further operations on a dataset¶
Script option¶
As we reported in Section ‘Query Dataset’, the script option can be very useful when the user wants to create a very dynamic query. Dealing with parameters, if the query syntax is not handled properly, the missing of one parameter value may compromise the dataset execution itself. In particular, it can be convenient to use a script to manage the assignment of null or empty values to parameters in those cases when the user wants the filters not to be applied.
Knowage query dataset are endowed of a specific area to insert the script syntax. Clicking on the “Script” button we reported in section Query Dataset’, the interface opens a wizard containing two tabs: the script tab is the one opened by default. Here the user is asked to select the language he/she’s intended to use.
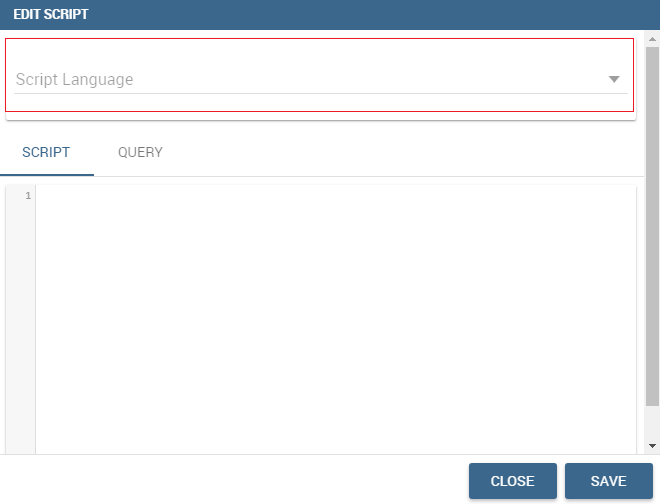
Editing script.¶
Typically, scripts are configured to load placeholders with a slice of SQL code. Referring to the following pictures, we show an example of JavaScript (JS) code usage. Moving to the “Query” tab the user has to insert a placeholder where he/she’s expecting a certain clause to be added. The query will then look like the one shown below.
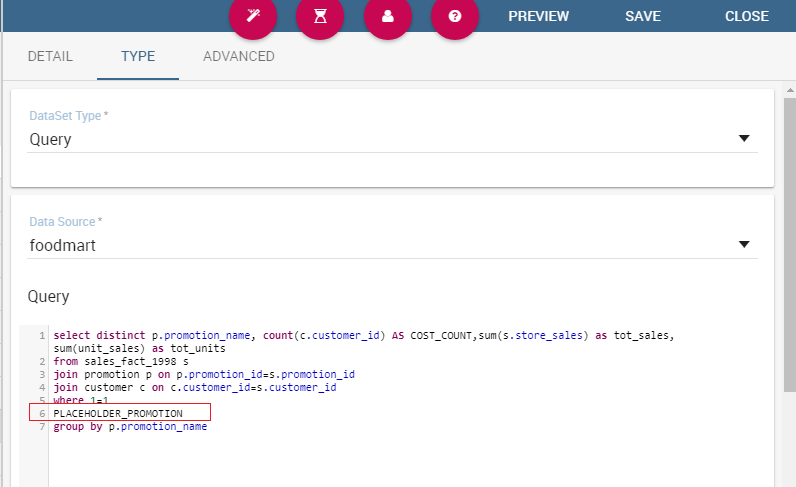
Setting placeholder using script.¶
Moving to the “Script” tab instead, the user has to declare how the server has to manage the placeholder. The following picture shows a JS block code where the user first initializes a variable as empty: if certain conditions, on one or more parameters, are satisfied, the variable is assigned an SQL code string. Then, the JS method “.replace” will substitute the placeholder with the content the variable.
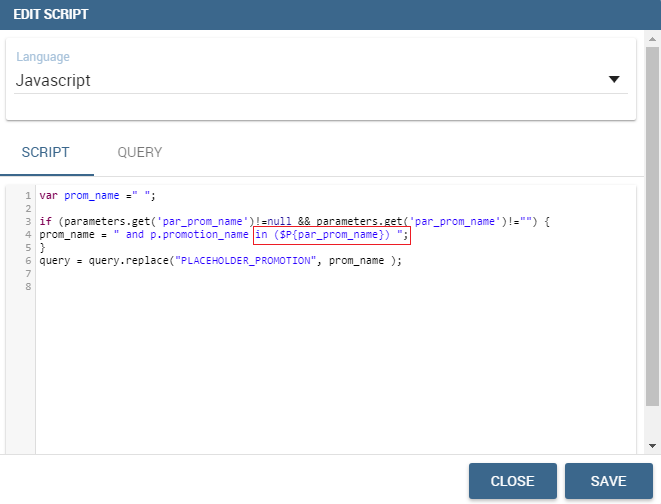
Editing script.¶
To sum up, the example reveals that if the parameter is assigned a null or empty value, conditions are not satisfied and the placeholder is substituted with an empty space (therefore nothing is added to the “where” clause). Otherwise, the SQL code is inserted into the “where” clause and the dataset is accordingly filtered.
We stress that it is not necessary to use any concatenation or JS method to recall for parameters’ values. It is enough to use the syntax $P{par_name} as well as seen when configuring a plain parametric dataset.
Transformations¶
In some cases it is useful to perform transformations on the results of a dataset, to obtain data in the desired format. The most common operation is the pivot transformation, which allows the switch between rows and columns of the dataset results. Knowage supports this operation on any type of dataset.
To set a pivot transformation, select Pivot Transformer in the drop down menu of the Transformation tab. Then set the following fields:
Name of Category Column to be Pivoted. Here you should write the name of the dataset column whose values will be mapped onto columns after pivoting.
Name of Value Column to be Pivoted. Here you should write the name of the result set column, whose values should become values of the previous columns (category columns).
Name of the Column not to be Pivoted. Here you should write the name of those columns that should not be altered during the transformation.
In case you wish to add a number to category columns (e.g., 1_name_of_column), you should check the option Automatic Columns numeration.
An example of usage is available in figure below, showing the result set of the dataset.
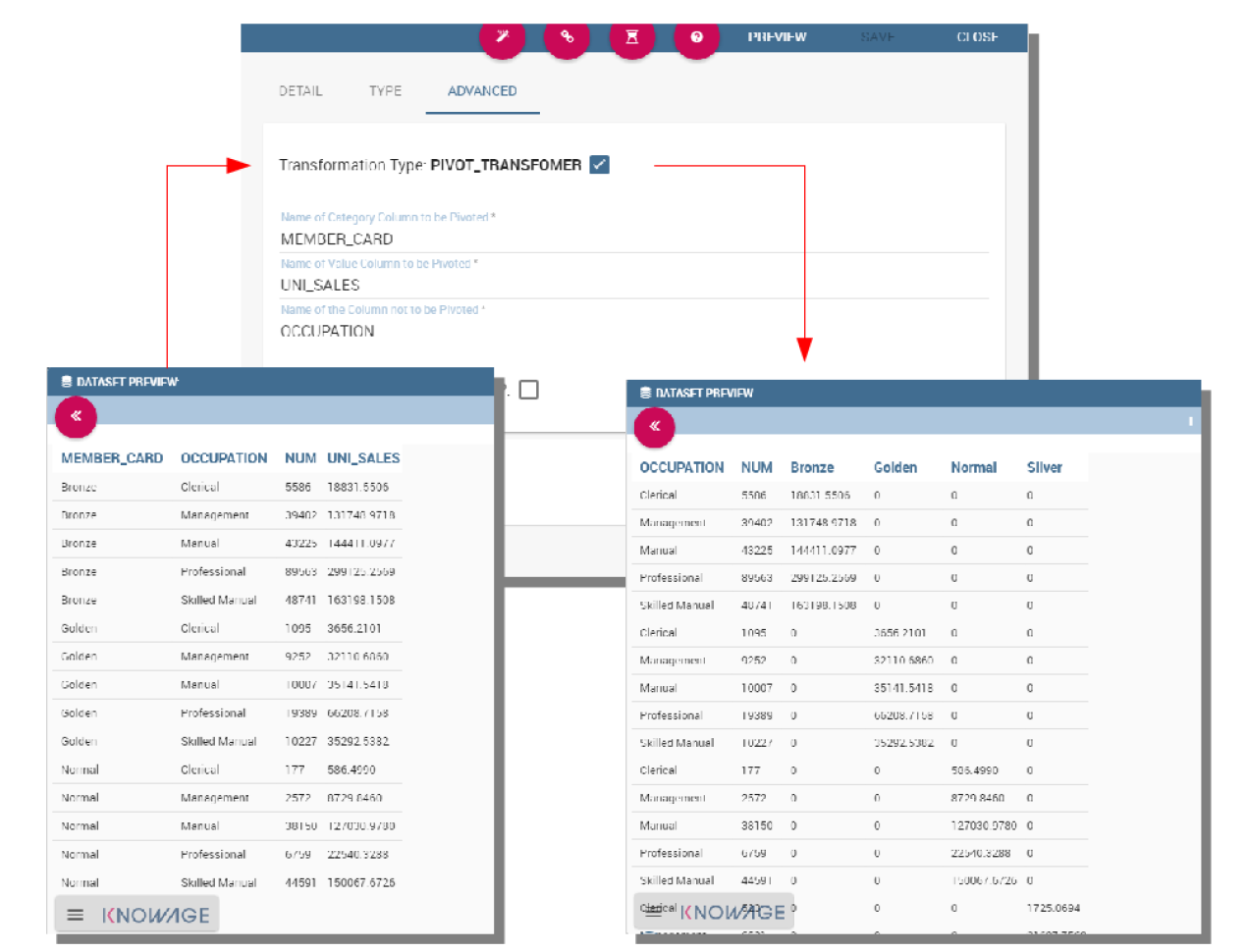
Pivot transformation.¶
Dataset persistence¶
The Advanced tab is used to make a dataset persistent, i.e., to write it on the default database. Making a dataset persistent may be useful in case dataset calculation takes a considerable amount of time. Instead of recalculating the dataset each time the documents using it are executed, the dataset is calculated once and then retrieved from a table to improve performance. In order to force recalculation of the dataset, you should execute dataset preview again. This will store the newly generated data on the database table.
Once marked the dataset as persistent, you are asked to insert a table name. This is the table where data are stored and then retrieved.
Important
Enterprise Edition only
With KnowageBD, KnowageER and KnowageSI products you can also decide to schedule the persistence operation: this means that the data stored in the table will be update with according to the frequency defined in the scheduling options. Choose your scheduling option and save the dataset. Now the table where your data are stored will be persisted according to the settings provided.
Preview¶
Before actually using the dataset in a document, it is a good practice to test it. Clicking the Preview button within the Preview tab, you can see a preview of the result set, see the following figure. This allows the developer to check any anomaly or possible error in the dataset definition, before using it.
Dataset preview (left) and parameters prompt window (right).¶
If some parameters have been set, a window with their list will be shown: their values must be entered by double clicking on the set to string, just write the value you want to assign in the preview: quotes will be added automatically. On the other hand, if the type is raw or generic but you want to input text, then remember to add quotes to the test value.